 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBagBERT: BERT-based bagging-stacking for multi-topic classification
Paper and Code
Nov 10, 2021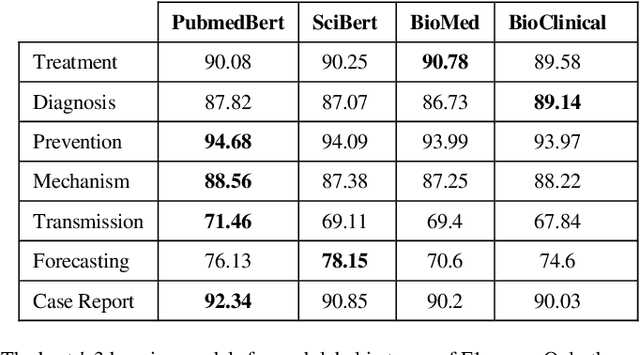
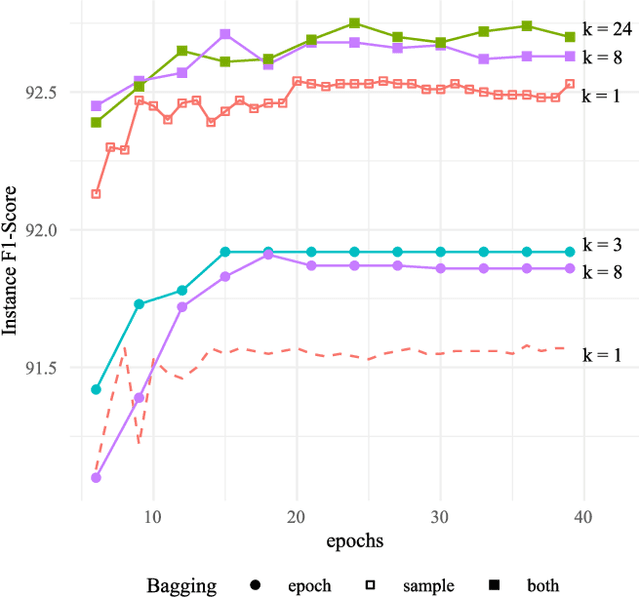
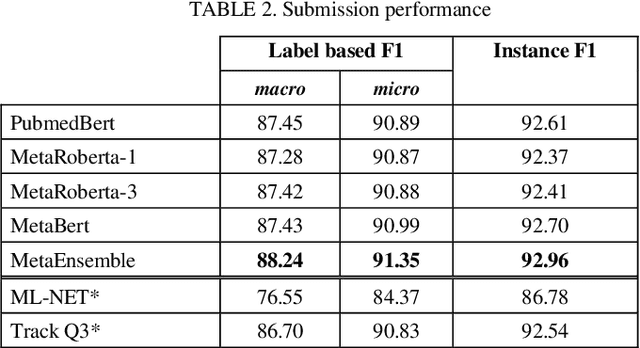
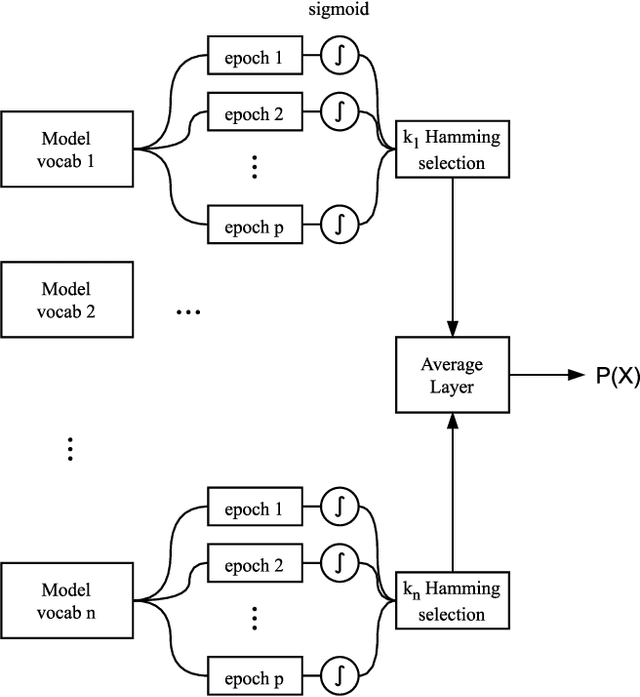
This paper describes our submission on the COVID-19 literature annotation task at Biocreative VII. We proposed an approach that exploits the knowledge of the globally non-optimal weights, usually rejected, to build a rich representation of each label. Our proposed approach consists of two stages: (1) A bagging of various initializations of the training data that features weakly trained weights, (2) A stacking of heterogeneous vocabulary models based on BERT and RoBERTa Embeddings. The aggregation of these weak insights performs better than a classical globally efficient model. The purpose is the distillation of the richness of knowledge to a simpler and lighter model. Our system obtains an Instance-based F1 of 92.96 and a Label-based micro-F1 of 91.35.