 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiently Detecting Overlapping Communities through Seeding and Semi-Supervised Learning
Sep 17, 2014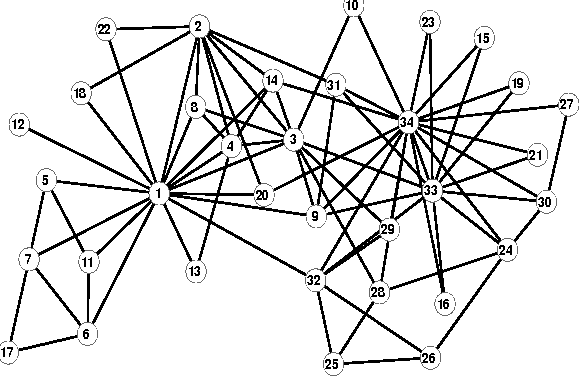

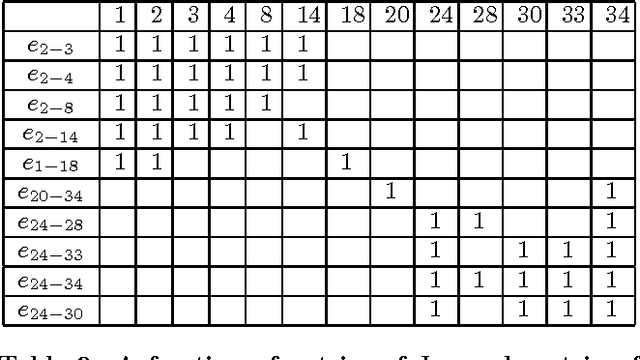
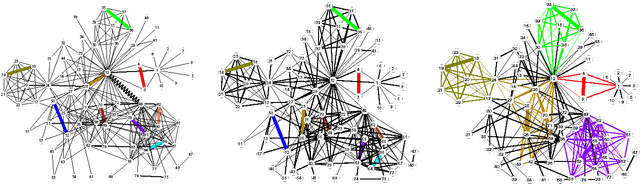
Seeding then expanding is a commonly used scheme to discover overlapping communities in a network. Most seeding methods are either too complex to scale to large networks or too simple to select high-quality seeds, and the non-principled functions used by most expanding methods lead to poor performance when applied to diverse networks. This paper proposes a new method that transforms a network into a corpus where each edge is treated as a document, and all nodes of the network are treated as terms of the corpus. An effective seeding method is also proposed that selects seeds as a training set, then a principled expanding method based on semi-supervised learning is applied to classify edges. We compare our new algorithm with four other community detection algorithms on a wide range of synthetic and empirical networks. Experimental results show that the new algorithm can significantly improve clustering performance in most cases. Furthermore, the time complexity of the new algorithm is linear to the number of edges, and this low complexity makes the new algorithm scalable to large networks.