 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Classification-Aware Super-Resolution Framework for Ship Targets in SAR Imagery
Aug 08, 2025High-resolution imagery plays a critical role in improving the performance of visual recognition tasks such as classification, detection, and segmentation. In many domains, including remote sensing and surveillance, low-resolution images can limit the accuracy of automated analysis. To address this, super-resolution (SR) techniques have been widely adopted to attempt to reconstruct high-resolution images from low-resolution inputs. Related traditional approaches focus solely on enhancing image quality based on pixel-level metrics, leaving the relationship between super-resolved image fidelity and downstream classification performance largely underexplored. This raises a key question: can integrating classification objectives directly into the super-resolution process further improve classification accuracy? In this paper, we try to respond to this question by investigating the relationship between super-resolution and classification through the deployment of a specialised algorithmic strategy. We propose a novel methodology that increases the resolution of synthetic aperture radar imagery by optimising loss functions that account for both image quality and classification performance. Our approach improves image quality, as measured by scientifically ascertained image quality indicators, while also enhancing classification accuracy.
Feature-Space Oversampling for Addressing Class Imbalance in SAR Ship Classification
Aug 08, 2025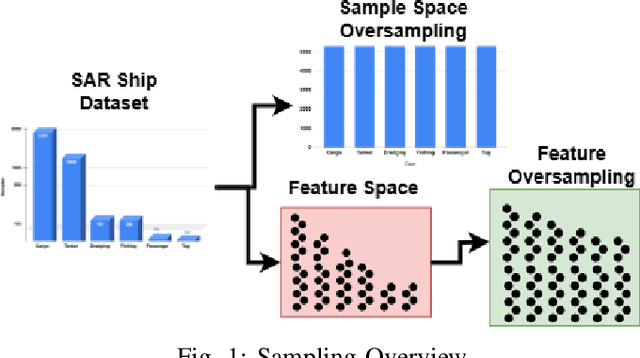
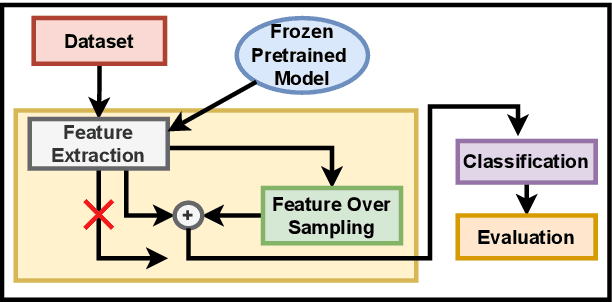
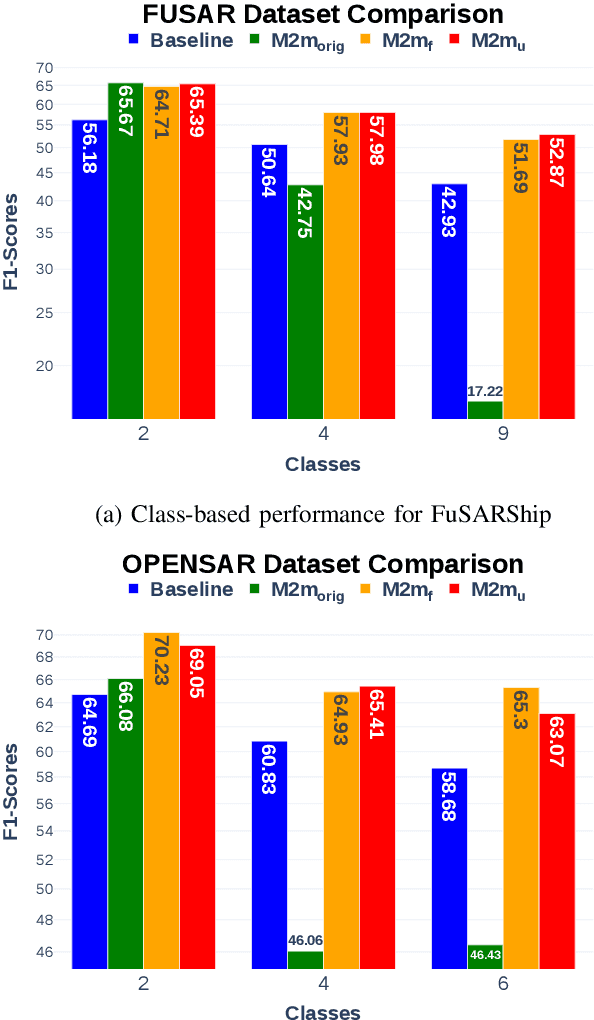
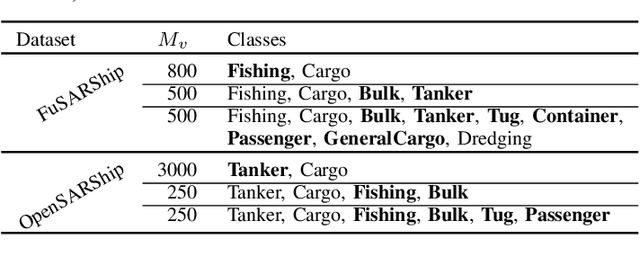
SAR ship classification faces the challenge of long-tailed datasets, which complicates the classification of underrepresented classes. Oversampling methods have proven effective in addressing class imbalance in optical data. In this paper, we evaluated the effect of oversampling in the feature space for SAR ship classification. We propose two novel algorithms inspired by the Major-to-minor (M2m) method M2m$_f$, M2m$_u$. The algorithms are tested on two public datasets, OpenSARShip (6 classes) and FuSARShip (9 classes), using three state-of-the-art models as feature extractors: ViT, VGG16, and ResNet50. Additionally, we also analyzed the impact of oversampling methods on different class sizes. The results demonstrated the effectiveness of our novel methods over the original M2m and baselines, with an average F1-score increase of 8.82% for FuSARShip and 4.44% for OpenSARShip.
A Survey on SAR ship classification using Deep Learning
Mar 14, 2025Deep learning (DL) has emerged as a powerful tool for Synthetic Aperture Radar (SAR) ship classification. This survey comprehensively analyzes the diverse DL techniques employed in this domain. We identify critical trends and challenges, highlighting the importance of integrating handcrafted features, utilizing public datasets, data augmentation, fine-tuning, explainability techniques, and fostering interdisciplinary collaborations to improve DL model performance. This survey establishes a first-of-its-kind taxonomy for categorizing relevant research based on DL models, handcrafted feature use, SAR attribute utilization, and the impact of fine-tuning. We discuss the methodologies used in SAR ship classification tasks and the impact of different techniques. Finally, the survey explores potential avenues for future research, including addressing data scarcity, exploring novel DL architectures, incorporating interpretability techniques, and establishing standardized performance metrics. By addressing these challenges and leveraging advancements in DL, researchers can contribute to developing more accurate and efficient ship classification systems, ultimately enhancing maritime surveillance and related applications.
A Meta-analytical Comparison of Naive Bayes and Random Forest for Software Defect Prediction
Jun 27, 2023



Is there a statistical difference between Naive Bayes and Random Forest in terms of recall, f-measure, and precision for predicting software defects? By utilizing systematic literature review and meta-analysis, we are answering this question. We conducted a systematic literature review by establishing criteria to search and choose papers, resulting in five studies. After that, using the meta-data and forest-plots of five chosen papers, we conducted a meta-analysis to compare the two models. The results have shown that there is no significant statistical evidence that Naive Bayes perform differently from Random Forest in terms of recall, f-measure, and precision.
* 11 pages, 8 figures, Conference Paper
What augmentations are sensitive to hyper-parameters and why?
Nov 06, 2021

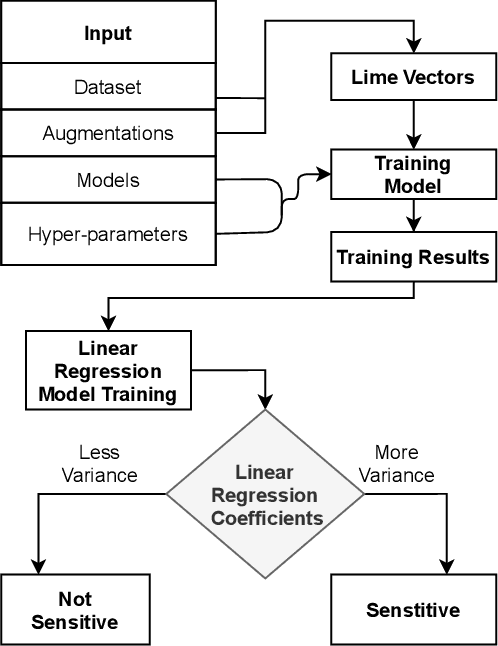
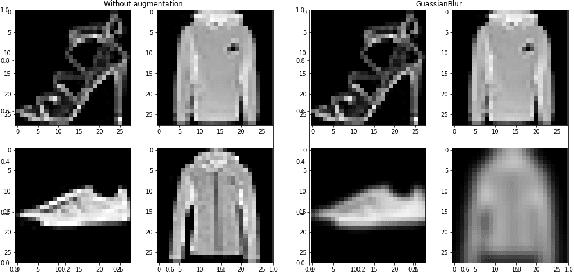
We apply augmentations to our dataset to enhance the quality of our predictions and make our final models more resilient to noisy data and domain drifts. Yet the question remains, how are these augmentations going to perform with different hyper-parameters? In this study we evaluate the sensitivity of augmentations with regards to the model's hyper parameters along with their consistency and influence by performing a Local Surrogate (LIME) interpretation on the impact of hyper-parameters when different augmentations are applied to a machine learning model. We have utilized Linear regression coefficients for weighing each augmentation. Our research has proved that there are some augmentations which are highly sensitive to hyper-parameters and others which are more resilient and reliable.