 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Dialogue Management: Quality Datasets vs Models
Oct 02, 2023Task-oriented dialogue systems (TODS) have become crucial for users to interact with machines and computers using natural language. One of its key components is the dialogue manager, which guides the conversation towards a good goal for the user by providing the best possible response. Previous works have proposed rule-based systems (RBS), reinforcement learning (RL), and supervised learning (SL) as solutions for the correct dialogue management; in other words, select the best response given input by the user. However, this work argues that the leading cause of DMs not achieving maximum performance resides in the quality of the datasets rather than the models employed thus far; this means that dataset errors, like mislabeling, originate a large percentage of failures in dialogue management. We studied the main errors in the most widely used datasets, Multiwoz 2.1 and SGD, to demonstrate this hypothesis. To do this, we have designed a synthetic dialogue generator to fully control the amount and type of errors introduced in the dataset. Using this generator, we demonstrated that errors in the datasets contribute proportionally to the performance of the models
Modularity as a Means for Complexity Management in Neural Networks Learning
Feb 25, 2019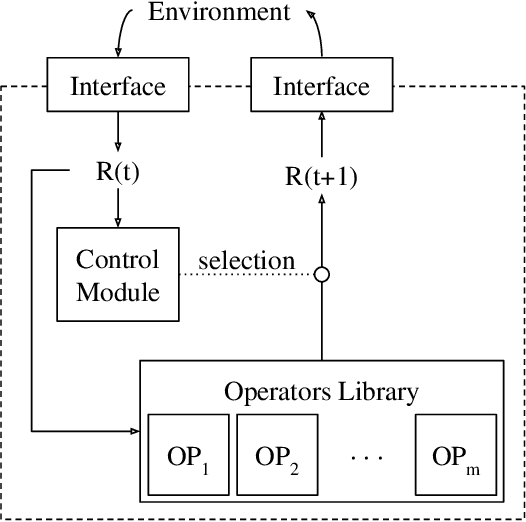
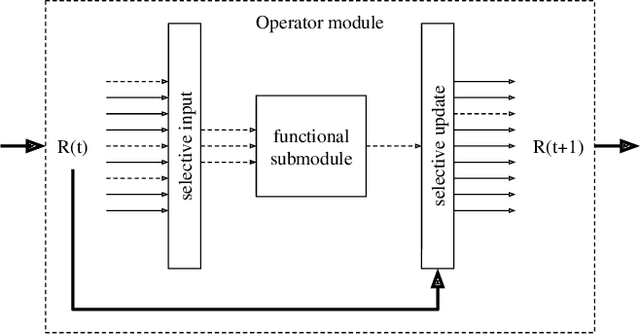
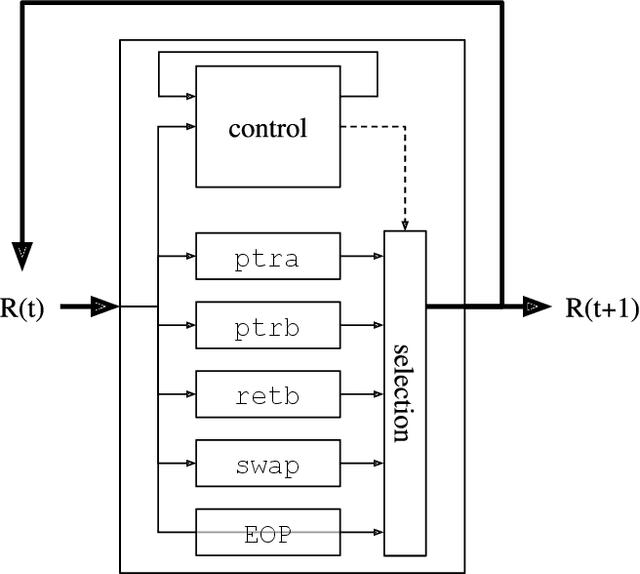
Training a Neural Network (NN) with lots of parameters or intricate architectures creates undesired phenomena that complicate the optimization process. To address this issue we propose a first modular approach to NN design, wherein the NN is decomposed into a control module and several functional modules, implementing primitive operations. We illustrate the modular concept by comparing performances between a monolithic and a modular NN on a list sorting problem and show the benefits in terms of training speed, training stability and maintainability. We also discuss some questions that arise in modular NNs.