 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal aggregation of audio-visual modalities for emotion recognition
Jul 08, 2020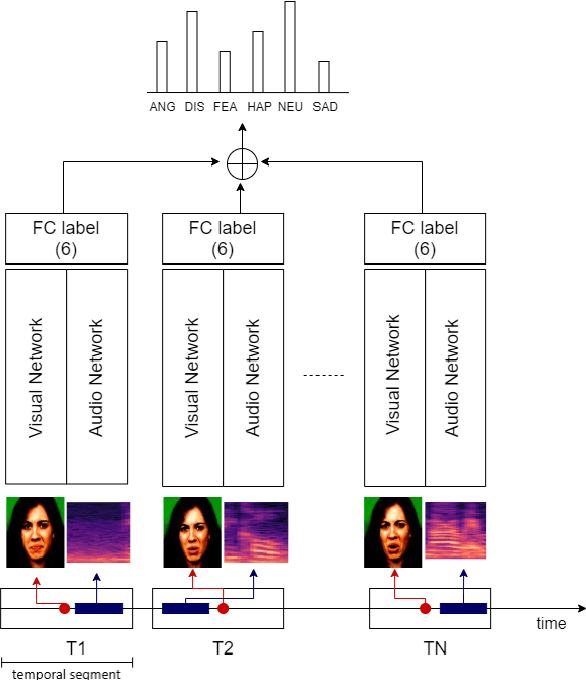
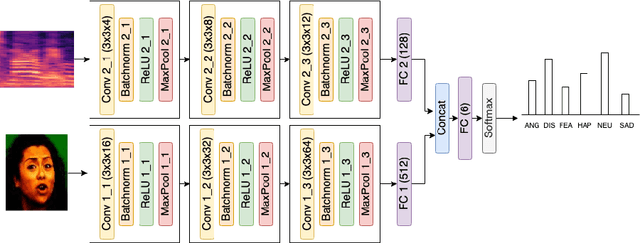

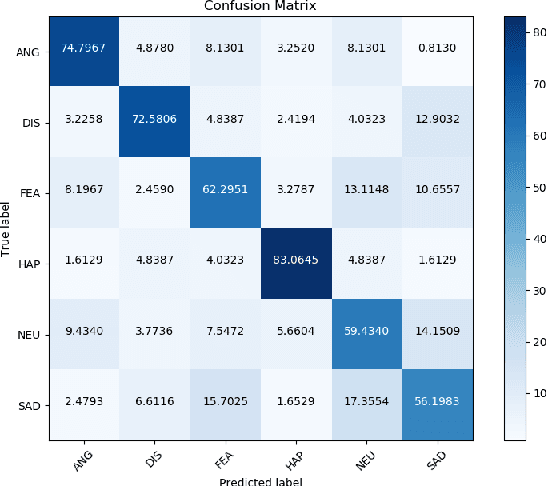
Emotion recognition has a pivotal role in affective computing and in human-computer interaction. The current technological developments lead to increased possibilities of collecting data about the emotional state of a person. In general, human perception regarding the emotion transmitted by a subject is based on vocal and visual information collected in the first seconds of interaction with the subject. As a consequence, the integration of verbal (i.e., speech) and non-verbal (i.e., image) information seems to be the preferred choice in most of the current approaches towards emotion recognition. In this paper, we propose a multimodal fusion technique for emotion recognition based on combining audio-visual modalities from a temporal window with different temporal offsets for each modality. We show that our proposed method outperforms other methods from the literature and human accuracy rating. The experiments are conducted over the open-access multimodal dataset CREMA-D.