 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Uncertainty in Word Embeddings: GloVe-V
Jun 18, 2024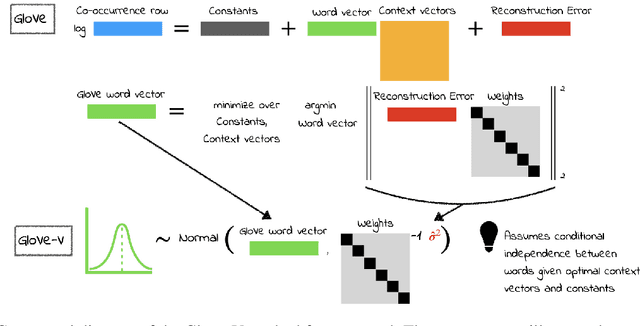
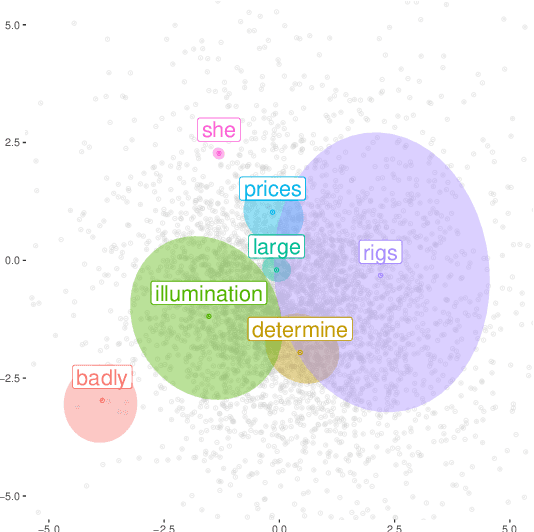

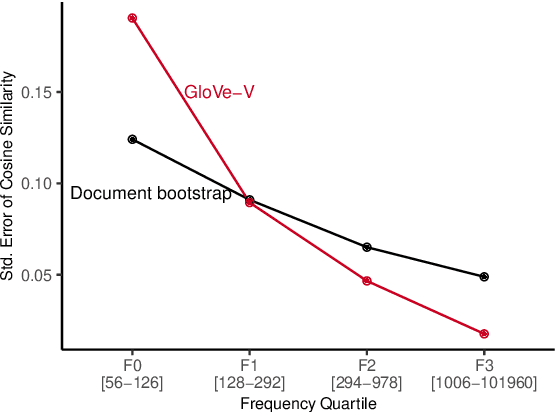
Static word embeddings are ubiquitous in computational social science applications and contribute to practical decision-making in a variety of fields including law and healthcare. However, assessing the statistical uncertainty in downstream conclusions drawn from word embedding statistics has remained challenging. When using only point estimates for embeddings, researchers have no streamlined way of assessing the degree to which their model selection criteria or scientific conclusions are subject to noise due to sparsity in the underlying data used to generate the embeddings. We introduce a method to obtain approximate, easy-to-use, and scalable reconstruction error variance estimates for GloVe (Pennington et al., 2014), one of the most widely used word embedding models, using an analytical approximation to a multivariate normal model. To demonstrate the value of embeddings with variance (GloVe-V), we illustrate how our approach enables principled hypothesis testing in core word embedding tasks, such as comparing the similarity between different word pairs in vector space, assessing the performance of different models, and analyzing the relative degree of ethnic or gender bias in a corpus using different word lists.