 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Benefit Of Temporally-Strong Labels In Audio Event Classification
May 14, 2021
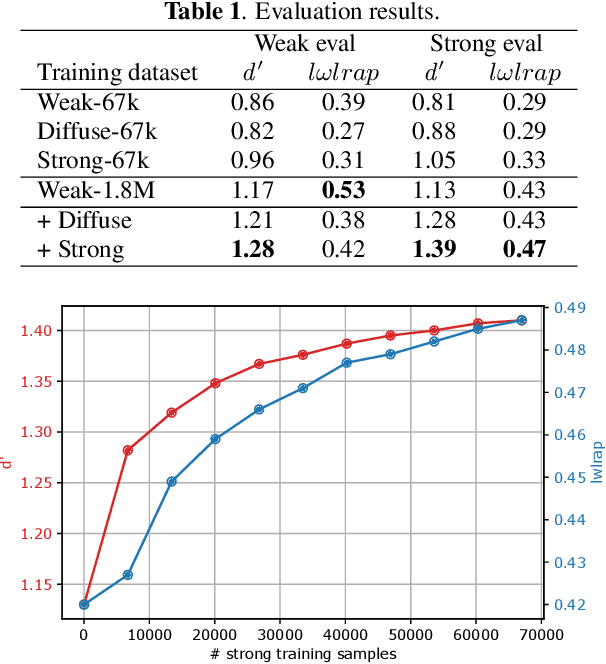
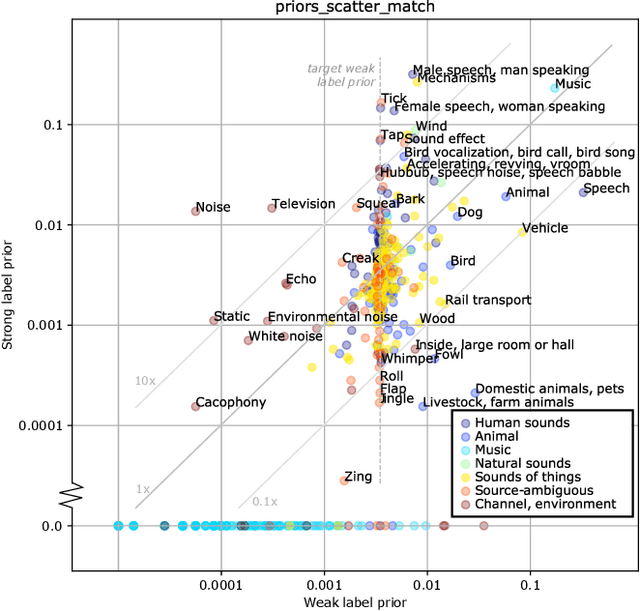
To reveal the importance of temporal precision in ground truth audio event labels, we collected precise (~0.1 sec resolution) "strong" labels for a portion of the AudioSet dataset. We devised a temporally strong evaluation set (including explicit negatives of varying difficulty) and a small strong-labeled training subset of 67k clips (compared to the original dataset's 1.8M clips labeled at 10 sec resolution). We show that fine-tuning with a mix of weak and strongly labeled data can substantially improve classifier performance, even when evaluated using only the original weak labels. For a ResNet50 architecture, d' on the strong evaluation data including explicit negatives improves from 1.13 to 1.41. The new labels are available as an update to AudioSet.