Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeyphrase Extraction : Enhancing Lists
Apr 01, 2012
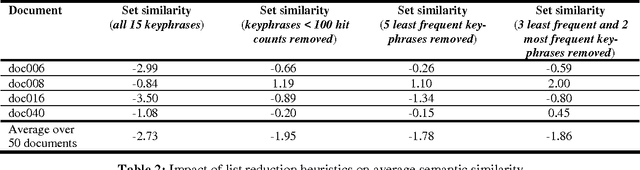


This paper proposes some modest improvements to Extractor, a state-of-the-art keyphrase extraction system, by using a terabyte-sized corpus to estimate the informativeness and semantic similarity of keyphrases. We present two techniques to improve the organization and remove outliers of lists of keyphrases. The first is a simple ordering according to their occurrences in the corpus; the second is clustering according to semantic similarity. Evaluation issues are discussed. We present a novel technique of comparing extracted keyphrases to a gold standard which relies on semantic similarity rather than string matching or an evaluation involving human judges.
* 8 pages; Proceedings of the 2nd Conference on Computational
Linguistics in the North-East (CLiNE 2004), Montr\'eal, Canada, August
Via