 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Pixels to Explanations: Interpretable Diabetic Retinopathy Grading with CNN-Transformer Ensembles, Visual Explainability and Vision-Language Models
Apr 25, 2026The quality of diabetic retinopathy (DR) screening relies on the ability to correctly grade severity; however, many deep-learning (DL) classifiers cannot be easily interpreted in the clinical context. This study presents a methodology that combines strong discriminative models with multimodal explanations, converting retinal pixels into clinically interpretable outputs. Using the APTOS 2019 benchmark, we evaluated six representative CNN- and transformer-based backbones under a controlled protocol with stratified five-fold cross-validation. We then compared ensembling strategies (hard voting, weighted soft voting, stacking) and investigated a hybrid class-level fusion variant to exploit grade-specific advantages. For interpretability, we produced Grad-CAM++ visual attribution maps and short textual rationales using vision-language models (VLMs) conditioned on the fundus image and classifier outputs under conservative prompting constraints. Modern CNN backbones (ResNet-50 and ConvNeXt-Tiny) provided the strongest single-model baselines, with cross-validated QWK up to 0.919 and 0.914, respectively. Ensembling improved ordinal agreement, and weighted soft voting was the most consistent across folds (QWK 0.934 +/- 0.017). Hybrid class-level fusion was competitive but did not yield a statistically reliable improvement over standard fusion in paired fold comparisons (Holm-adjusted p >= 1.000). For explanation quality, Grad-CAM++ offered plausible but coarse localization, and VLM rationales were generally grade-consistent. Quantitatively, VLM variants showed a trade-off between clinical completeness and template-level semantic similarity (coverage 0.700 vs. BERTScore 0.072), while image-text alignment was comparable (CLIPScore approximately 0.34).
Transformer-Based Multi-Modal Temporal Embeddings for Explainable Metabolic Phenotyping in Type 1 Diabetes
Jan 07, 2026Type 1 diabetes (T1D) is a highly metabolically heterogeneous disease that cannot be adequately characterized by conventional biomarkers such as glycated hemoglobin (HbA1c). This study proposes an explainable deep learning framework that integrates continuous glucose monitoring (CGM) data with laboratory profiles to learn multimodal temporal embeddings of individual metabolic status. Temporal dependencies across modalities are modeled using a transformer encoder, while latent metabolic phenotypes are identified via Gaussian mixture modeling. Model interpretability is achieved through transformer attention visualization and SHAP-based feature attribution. Five latent metabolic phenotypes, ranging from metabolic stability to elevated cardiometabolic risk, were identified among 577 individuals with T1D. These phenotypes exhibit distinct biochemical profiles, including differences in glycemic control, lipid metabolism, renal markers, and thyrotropin (TSH) levels. Attention analysis highlights glucose variability as a dominant temporal factor, while SHAP analysis identifies HbA1c, triglycerides, cholesterol, creatinine, and TSH as key contributors to phenotype differentiation. Phenotype membership shows statistically significant, albeit modest, associations with hypertension, myocardial infarction, and heart failure. Overall, this explainable multimodal temporal embedding framework reveals physiologically coherent metabolic subgroups in T1D and supports risk stratification beyond single biomarkers.
Towards Transparent and Accurate Diabetes Prediction Using Machine Learning and Explainable Artificial Intelligence
Jan 30, 2025



Diabetes mellitus (DM) is a global health issue of significance that must be diagnosed as early as possible and managed well. This study presents a framework for diabetes prediction using Machine Learning (ML) models, complemented with eXplainable Artificial Intelligence (XAI) tools, to investigate both the predictive accuracy and interpretability of the predictions from ML models. Data Preprocessing is based on the Synthetic Minority Oversampling Technique (SMOTE) and feature scaling used on the Diabetes Binary Health Indicators dataset to deal with class imbalance and variability of clinical features. The ensemble model provided high accuracy, with a test accuracy of 92.50% and an ROC-AUC of 0.975. BMI, Age, General Health, Income, and Physical Activity were the most influential predictors obtained from the model explanations. The results of this study suggest that ML combined with XAI is a promising means of developing accurate and computationally transparent tools for use in healthcare systems.
Advances in Artificial Intelligence forDiabetes Prediction: Insights from a Systematic Literature Review
Dec 19, 2024This systematic review explores the use of machine learning (ML) in predicting diabetes, focusing on datasets, algorithms, training methods, and evaluation metrics. It examines datasets like the Singapore National Diabetic Retinopathy Screening program, REPLACE-BG, National Health and Nutrition Examination Survey, and Pima Indians Diabetes Database. The review assesses the performance of ML algorithms like CNN, SVM, Logistic Regression, and XGBoost in predicting diabetes outcomes. The study emphasizes the importance of interdisciplinary collaboration and ethical considerations in ML-based diabetes prediction models.
Detecting Privacy Requirements from User Stories with NLP Transfer Learning Models
Feb 02, 2022
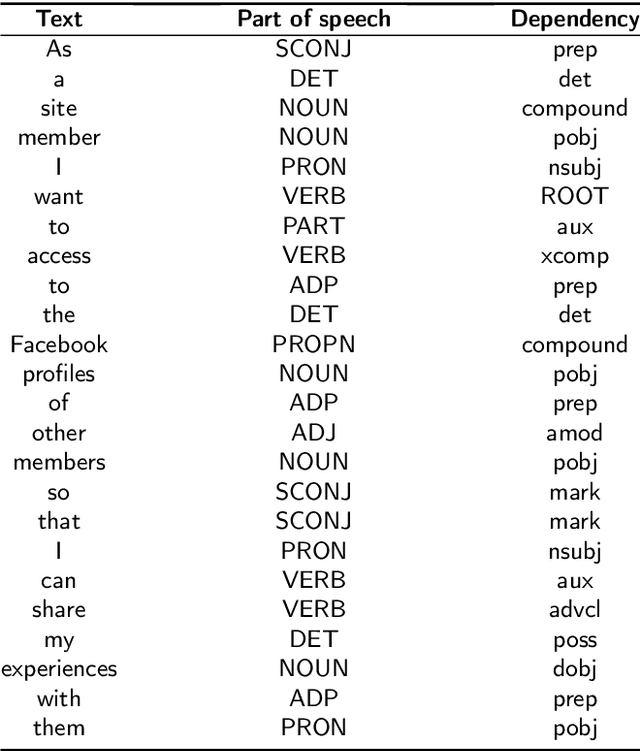
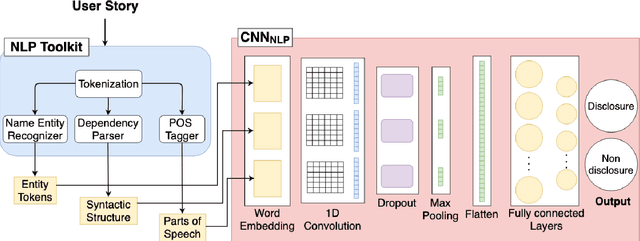
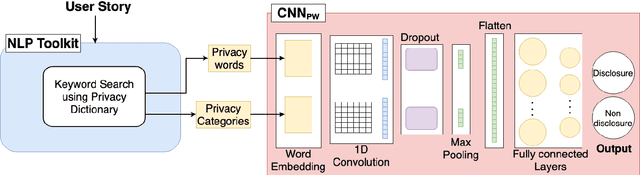
To provide privacy-aware software systems, it is crucial to consider privacy from the very beginning of the development. However, developers do not have the expertise and the knowledge required to embed the legal and social requirements for data protection into software systems. Objective: We present an approach to decrease privacy risks during agile software development by automatically detecting privacy-related information in the context of user story requirements, a prominent notation in agile Requirement Engineering (RE). Methods: The proposed approach combines Natural Language Processing (NLP) and linguistic resources with deep learning algorithms to identify privacy aspects into User Stories. NLP technologies are used to extract information regarding the semantic and syntactic structure of the text. This information is then processed by a pre-trained convolutional neural network, which paved the way for the implementation of a Transfer Learning technique. We evaluate the proposed approach by performing an empirical study with a dataset of 1680 user stories. Results: The experimental results show that deep learning algorithms allow to obtain better predictions than those achieved with conventional (shallow) machine learning methods. Moreover, the application of Transfer Learning allows to considerably improve the accuracy of the predictions, ca. 10%. Conclusions: Our study contributes to encourage software engineering researchers in considering the opportunities to automate privacy detection in the early phase of design, by also exploiting transfer learning models.