 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning, stochastic gradient descent and diffusion maps
Apr 06, 2022

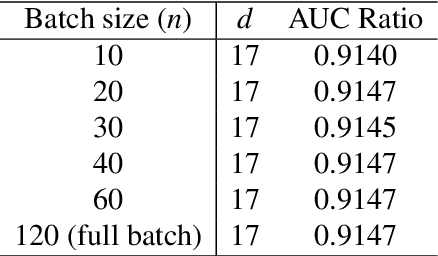
Stochastic gradient descent (SGD) is widely used in deep learning due to its computational efficiency but a complete understanding of why SGD performs so well remains a major challenge. It has been observed empirically that most eigenvalues of the Hessian of the loss functions on the loss landscape of over-parametrized deep networks are close to zero, while only a small number of eigenvalues are large. Zero eigenvalues indicate zero diffusion along the corresponding directions. This indicates that the process of minima selection mainly happens in the relatively low-dimensional subspace corresponding to top eigenvalues of the Hessian. Although the parameter space is very high-dimensional, these findings seems to indicate that the SGD dynamics may mainly live on a low-dimensional manifold. In this paper we pursue a truly data driven approach to the problem of getting a potentially deeper understanding of the high-dimensional parameter surface, and in particular of the landscape traced out by SGD, by analyzing the data generated through SGD, or any other optimizer for that matter, in order to possibly discovery (local) low-dimensional representations of the optimization landscape. As our vehicle for the exploration we use diffusion maps introduced by R. Coifman and coauthors.
Long Short-Term Memory Neural Network for Financial Time Series
Jan 20, 2022


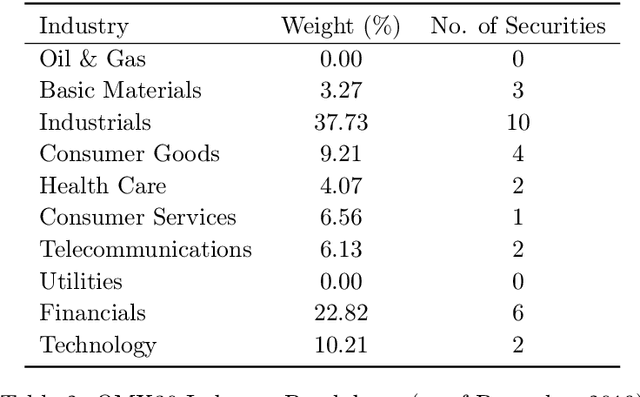
Performance forecasting is an age-old problem in economics and finance. Recently, developments in machine learning and neural networks have given rise to non-linear time series models that provide modern and promising alternatives to traditional methods of analysis. In this paper, we present an ensemble of independent and parallel long short-term memory (LSTM) neural networks for the prediction of stock price movement. LSTMs have been shown to be especially suited for time series data due to their ability to incorporate past information, while neural network ensembles have been found to reduce variability in results and improve generalization. A binary classification problem based on the median of returns is used, and the ensemble's forecast depends on a threshold value, which is the minimum number of LSTMs required to agree upon the result. The model is applied to the constituents of the smaller, less efficient Stockholm OMX30 instead of other major market indices such as the DJIA and S&P500 commonly found in literature. With a straightforward trading strategy, comparisons with a randomly chosen portfolio and a portfolio containing all the stocks in the index show that the portfolio resulting from the LSTM ensemble provides better average daily returns and higher cumulative returns over time. Moreover, the LSTM portfolio also exhibits less volatility, leading to higher risk-return ratios.