 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical analysis of word flow among five Indo-European languages
Jan 17, 2023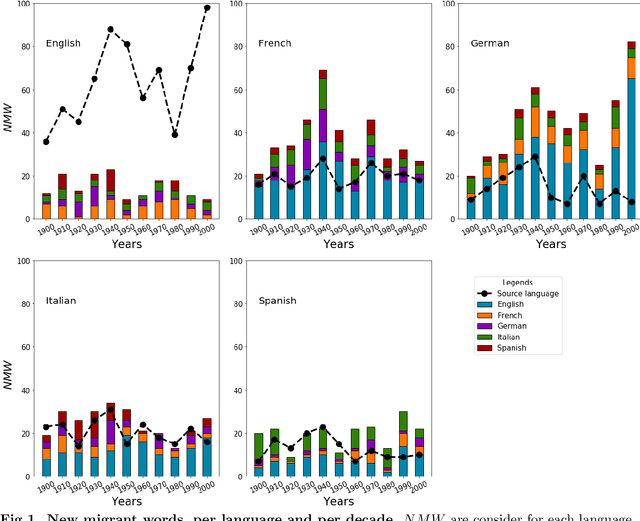
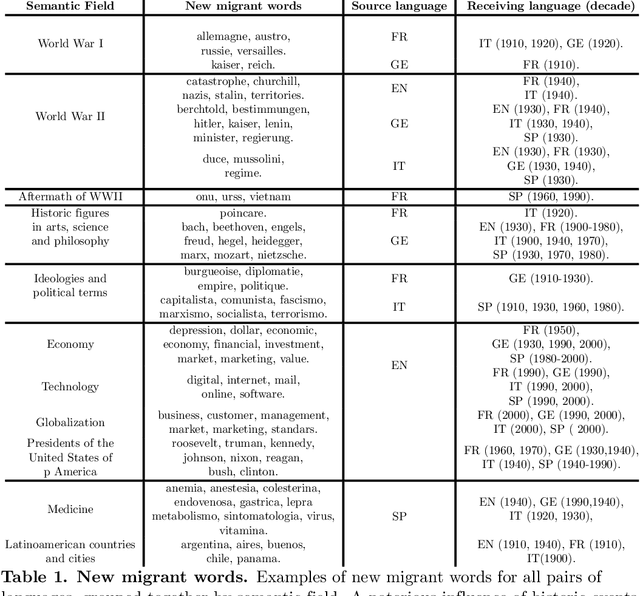
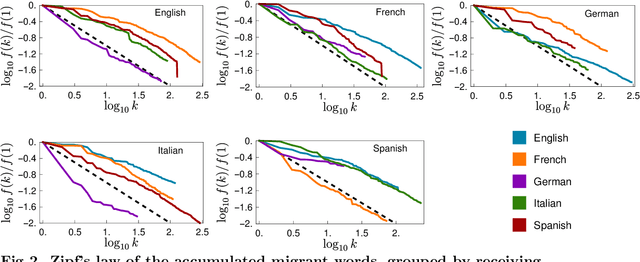
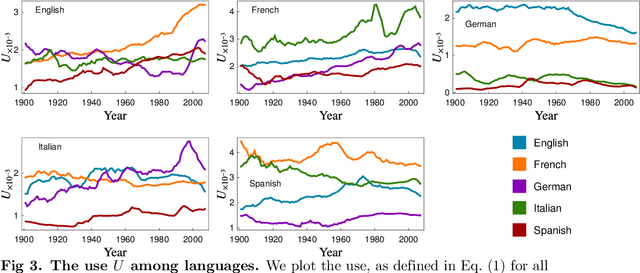
A recent increase in data availability has allowed the possibility to perform different statistical linguistic studies. Here we use the Google Books Ngram dataset to analyze word flow among English, French, German, Italian, and Spanish. We study what we define as ``migrant words'', a type of loanwords that do not change their spelling. We quantify migrant words from one language to another for different decades, and notice that most migrant words can be aggregated in semantic fields and associated to historic events. We also study the statistical properties of accumulated migrant words and their rank dynamics. We propose a measure of use of migrant words that could be used as a proxy of cultural influence. Our methodology is not exempt of caveats, but our results are encouraging to promote further studies in this direction.
Language statistics at different spatial, temporal, and grammatical scales
Jul 02, 2022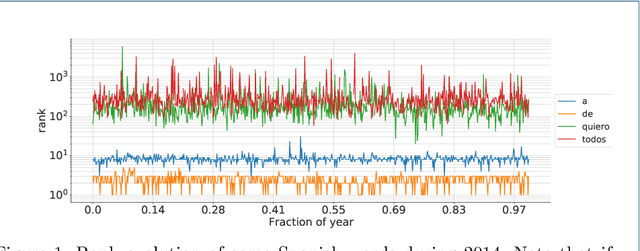
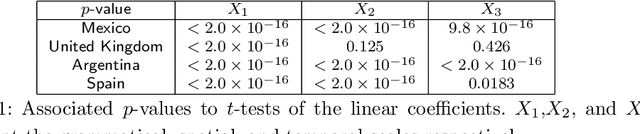
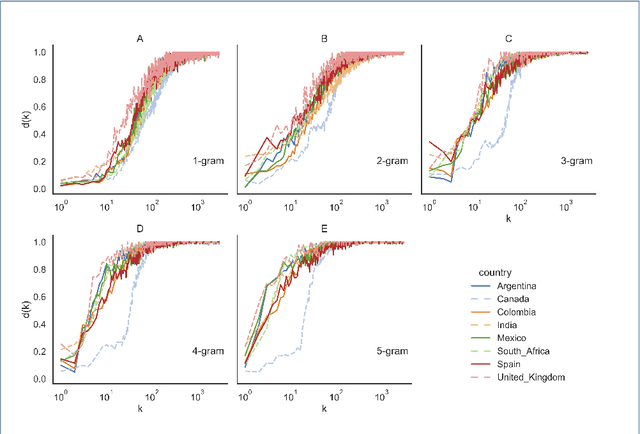

Statistical linguistics has advanced considerably in recent decades as data has become available. This has allowed researchers to study how statistical properties of languages change over time. In this work, we use data from Twitter to explore English and Spanish considering the rank diversity at different scales: temporal (from 3 to 96 hour intervals), spatial (from 3km to 3000+km radii), and grammatical (from monograms to pentagrams). We find that all three scales are relevant. However, the greatest changes come from variations in the grammatical scale. At the lowest grammatical scale (monograms), the rank diversity curves are most similar, independently on the values of other scales, languages, and countries. As the grammatical scale grows, the rank diversity curves vary more depending on the temporal and spatial scales, as well as on the language and country. We also study the statistics of Twitter-specific tokens: emojis, hashtags, and user mentions. These particular type of tokens show a sigmoid kind of behaviour as a rank diversity function. Our results are helpful to quantify aspects of language statistics that seem universal and what may lead to variations.
Rank diversity of languages: Generic behavior in computational linguistics
May 14, 2015Statistical studies of languages have focused on the rank-frequency distribution of words. Instead, we introduce here a measure of how word ranks change in time and call this distribution \emph{rank diversity}. We calculate this diversity for books published in six European languages since 1800, and find that it follows a universal lognormal distribution. Based on the mean and standard deviation associated with the lognormal distribution, we define three different word regimes of languages: "heads" consist of words which almost do not change their rank in time, "bodies" are words of general use, while "tails" are comprised by context-specific words and vary their rank considerably in time. The heads and bodies reflect the size of language cores identified by linguists for basic communication. We propose a Gaussian random walk model which reproduces the rank variation of words in time and thus the diversity. Rank diversity of words can be understood as the result of random variations in rank, where the size of the variation depends on the rank itself. We find that the core size is similar for all languages studied.