 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical analysis of word flow among five Indo-European languages
Paper and Code
Jan 17, 2023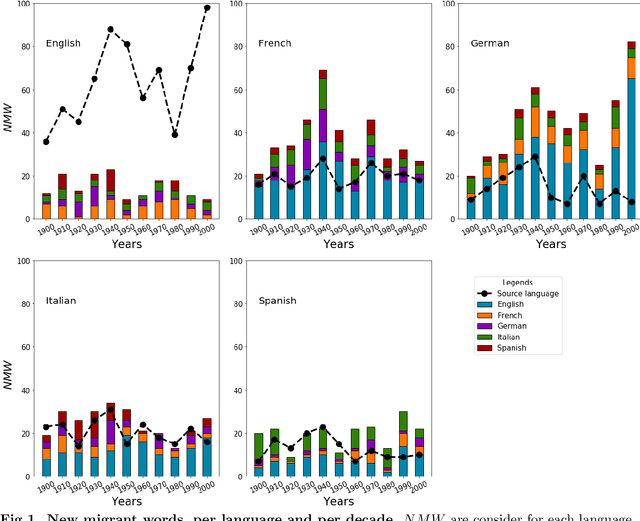
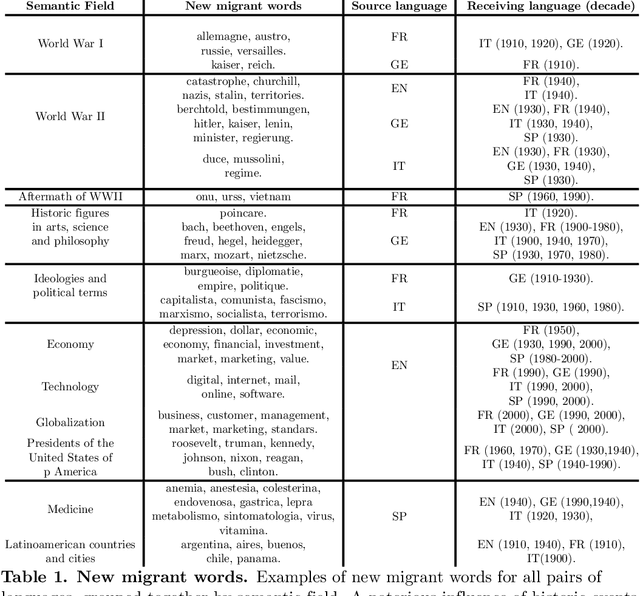
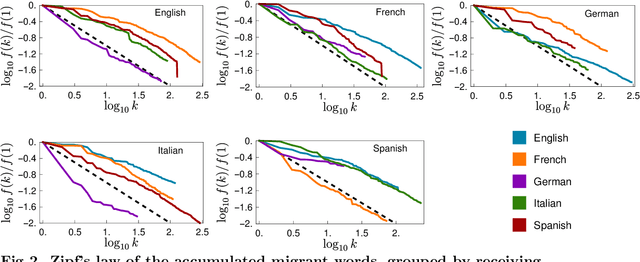
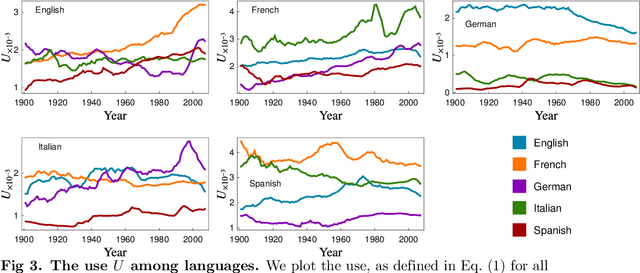
A recent increase in data availability has allowed the possibility to perform different statistical linguistic studies. Here we use the Google Books Ngram dataset to analyze word flow among English, French, German, Italian, and Spanish. We study what we define as ``migrant words'', a type of loanwords that do not change their spelling. We quantify migrant words from one language to another for different decades, and notice that most migrant words can be aggregated in semantic fields and associated to historic events. We also study the statistical properties of accumulated migrant words and their rank dynamics. We propose a measure of use of migrant words that could be used as a proxy of cultural influence. Our methodology is not exempt of caveats, but our results are encouraging to promote further studies in this direction.