 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelict landslide detection in rainforest areas using a combination of k-means clustering algorithm and Deep-Learning semantic segmentation models
Aug 04, 2022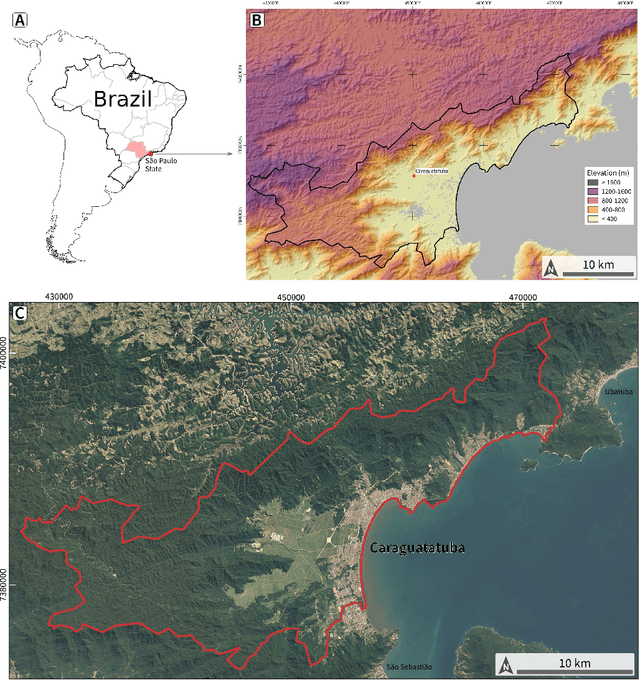

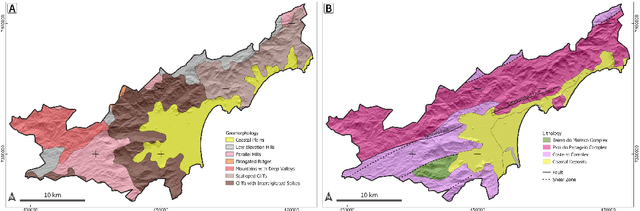
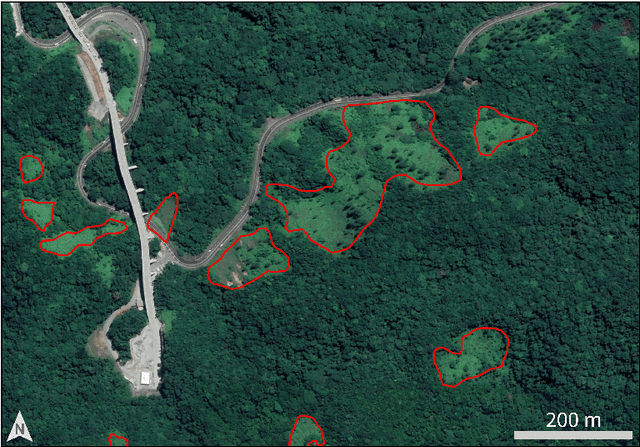
Landslides are destructive and recurrent natural disasters on steep slopes and represent a risk to lives and properties. Knowledge of relict landslides' location is vital to understand their mechanisms, update inventory maps and improve risk assessment. However, relict landslide mapping is complex in tropical regions covered with rainforest vegetation. A new CNN approach is proposed for semi-automatic detection of relict landslides, which uses a dataset generated by a k-means clustering algorithm and has a pre-training step. The weights computed in the pre-training are used to fine-tune the CNN training process. A comparison between the proposed and standard approaches is performed using CBERS-4A WPM images. Three CNNs for semantic segmentation are used (U-Net, FPN, Linknet) with two augmented datasets. A total of 42 combinations of CNNs are tested. Values of precision and recall were very similar between the combinations tested. Recall was higher than 75\% for every combination, but precision values were usually smaller than 20\%. False positives (FP) samples were addressed as the cause for these low precision values. Predictions of the proposed approach were more accurate and correctly detected more landslides. This work demonstrates that there are limitations for detecting relict landslides in areas covered with rainforest, mainly related to similarities between the spectral response of pastures and deforested areas with \textit{Gleichenella sp.} ferns, commonly used as an indicator of landslide scars.
Landslide Segmentation with U-Net: Evaluating Different Sampling Methods and Patch Sizes
Jul 13, 2020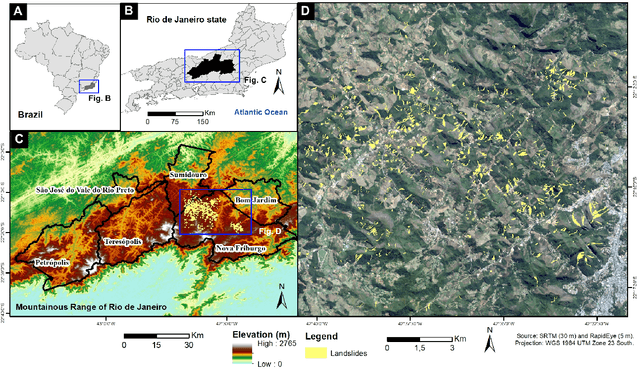


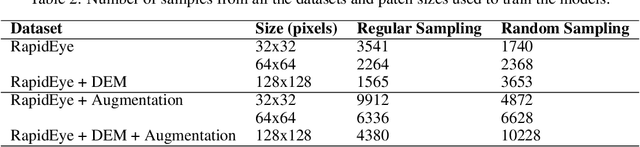
Landslide inventory maps are crucial to validate predictive landslide models; however, since most mapping methods rely on visual interpretation or expert knowledge, detailed inventory maps are still lacking. This study used a fully convolutional deep learning model named U-net to automatically segment landslides in the city of Nova Friburgo, located in the mountainous range of Rio de Janeiro, southeastern Brazil. The objective was to evaluate the impact of patch sizes, sampling methods, and datasets on the overall accuracy of the models. The training data used the optical information from RapidEye satellite, and a digital elevation model (DEM) derived from the L-band sensor of the ALOS satellite. The data was sampled using random and regular grid methods and patched in three sizes (32x32, 64x64, and 128x128 pixels). The models were evaluated on two areas with precision, recall, f1-score, and mean intersect over union (mIoU) metrics. The results show that the models trained with 32x32 tiles tend to have higher recall values due to higher true positive rates; however, they misclassify more background areas as landslides (false positives). Models trained with 128x128 tiles usually achieve higher precision values because they make less false positive errors. In both test areas, DEM and augmentation increased the accuracy of the models. Random sampling helped in model generalization. Models trained with 128x128 random tiles from the data that used the RapidEye image, DEM information, and augmentation achieved the highest f1-score, 0.55 in test area one, and 0.58 in test area two. The results achieved in this study are comparable to other fully convolutional models found in the literature, increasing the knowledge in the area.