 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Detectability of Active Gradient Inversion Attacks in Federated Learning
Nov 13, 2025

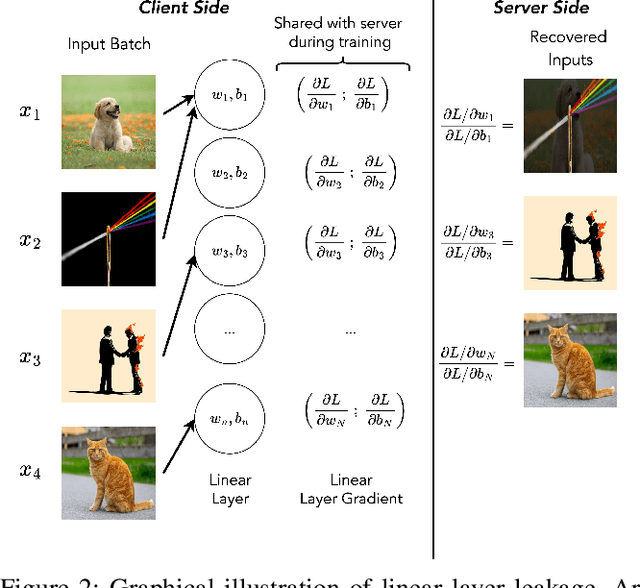

One of the key advantages of Federated Learning (FL) is its ability to collaboratively train a Machine Learning (ML) model while keeping clients' data on-site. However, this can create a false sense of security. Despite not sharing private data increases the overall privacy, prior studies have shown that gradients exchanged during the FL training remain vulnerable to Gradient Inversion Attacks (GIAs). These attacks allow reconstructing the clients' local data, breaking the privacy promise of FL. GIAs can be launched by either a passive or an active server. In the latter case, a malicious server manipulates the global model to facilitate data reconstruction. While effective, earlier attacks falling under this category have been demonstrated to be detectable by clients, limiting their real-world applicability. Recently, novel active GIAs have emerged, claiming to be far stealthier than previous approaches. This work provides the first comprehensive analysis of these claims, investigating four state-of-the-art GIAs. We propose novel lightweight client-side detection techniques, based on statistically improbable weight structures and anomalous loss and gradient dynamics. Extensive evaluation across several configurations demonstrates that our methods enable clients to effectively detect active GIAs without any modifications to the FL training protocol.
SoK: Security and Privacy of AI Agents for Blockchain
Sep 08, 2025

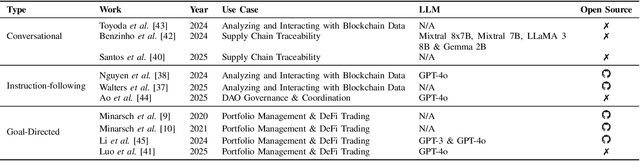

Blockchain and smart contracts have garnered significant interest in recent years as the foundation of a decentralized, trustless digital ecosystem, thereby eliminating the need for traditional centralized authorities. Despite their central role in powering Web3, their complexity still presents significant barriers for non-expert users. To bridge this gap, Artificial Intelligence (AI)-based agents have emerged as valuable tools for interacting with blockchain environments, supporting a range of tasks, from analyzing on-chain data and optimizing transaction strategies to detecting vulnerabilities within smart contracts. While interest in applying AI to blockchain is growing, the literature still lacks a comprehensive survey that focuses specifically on the intersection with AI agents. Most of the related work only provides general considerations, without focusing on any specific domain. This paper addresses this gap by presenting the first Systematization of Knowledge dedicated to AI-driven systems for blockchain, with a special focus on their security and privacy dimensions, shedding light on their applications, limitations, and future research directions.
Federated Unlearning Made Practical: Seamless Integration via Negated Pseudo-Gradients
Apr 08, 2025



The right to be forgotten is a fundamental principle of privacy-preserving regulations and extends to Machine Learning (ML) paradigms such as Federated Learning (FL). While FL enhances privacy by enabling collaborative model training without sharing private data, trained models still retain the influence of training data. Federated Unlearning (FU) methods recently proposed often rely on impractical assumptions for real-world FL deployments, such as storing client update histories or requiring access to a publicly available dataset. To address these constraints, this paper introduces a novel method that leverages negated Pseudo-gradients Updates for Federated Unlearning (PUF). Our approach only uses standard client model updates, anyway employed during regular FL rounds, and interprets them as pseudo-gradients. When a client needs to be forgotten, we apply the negated of their pseudo-gradients, appropriately scaled, to the global model. Unlike state-of-the-art mechanisms, PUF seamlessly integrates with FL workflows, incurs no additional computational and communication overhead beyond standard FL rounds, and supports concurrent unlearning requests. We extensively evaluated the proposed method on two well-known benchmark image classification datasets (CIFAR-10 and CIFAR-100) and a real-world medical imaging dataset for segmentation (ProstateMRI), using three different neural architectures: two residual networks and a vision transformer. The experimental results across various settings demonstrate that PUF achieves state-of-the-art forgetting effectiveness and recovery time, without relying on any additional assumptions, thus underscoring its practical applicability.
Federated Unlearning: A Survey on Methods, Design Guidelines, and Evaluation Metrics
Jan 10, 2024Federated Learning (FL) enables collaborative training of a Machine Learning (ML) model across multiple parties, facilitating the preservation of users' and institutions' privacy by keeping data stored locally. Instead of centralizing raw data, FL exchanges locally refined model parameters to build a global model incrementally. While FL is more compliant with emerging regulations such as the European General Data Protection Regulation (GDPR), ensuring the right to be forgotten in this context - allowing FL participants to remove their data contributions from the learned model - remains unclear. In addition, it is recognized that malicious clients may inject backdoors into the global model through updates, e.g. to generate mispredictions on specially crafted data examples. Consequently, there is the need for mechanisms that can guarantee individuals the possibility to remove their data and erase malicious contributions even after aggregation, without compromising the already acquired "good" knowledge. This highlights the necessity for novel Federated Unlearning (FU) algorithms, which can efficiently remove specific clients' contributions without full model retraining. This survey provides background concepts, empirical evidence, and practical guidelines to design/implement efficient FU schemes. Our study includes a detailed analysis of the metrics for evaluating unlearning in FL and presents an in-depth literature review categorizing state-of-the-art FU contributions under a novel taxonomy. Finally, we outline the most relevant and still open technical challenges, by identifying the most promising research directions in the field.