 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Task-Based Machine Learning Content Extraction Services for VIDINT
Jul 09, 2022

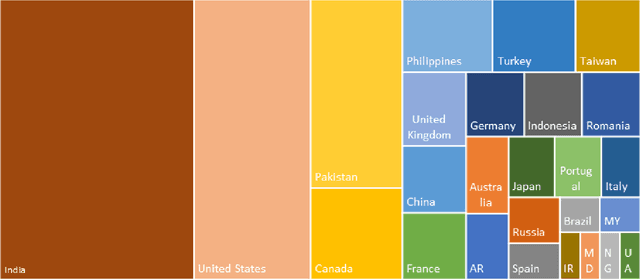

This paper provides a comparison of current video content extraction tools with a focus on comparing commercial task-based machine learning services. Video intelligence (VIDINT) data has become a critical intelligence source in the past decade. The need for AI-based analytics and automation tools to extract and structure content from video has quickly become a priority for organizations needing to search, analyze and exploit video at scale. With rapid growth in machine learning technology, the maturity of machine transcription, machine translation, topic tagging, and object recognition tasks are improving at an exponential rate, breaking performance records in speed and accuracy as new applications evolve. Each section of this paper reviews and compares products, software resources and video analytics capabilities based on tasks relevant to extracting information from video with machine learning techniques.
Towards automatic extractive text summarization of A-133 Single Audit reports with machine learning
Nov 08, 2019

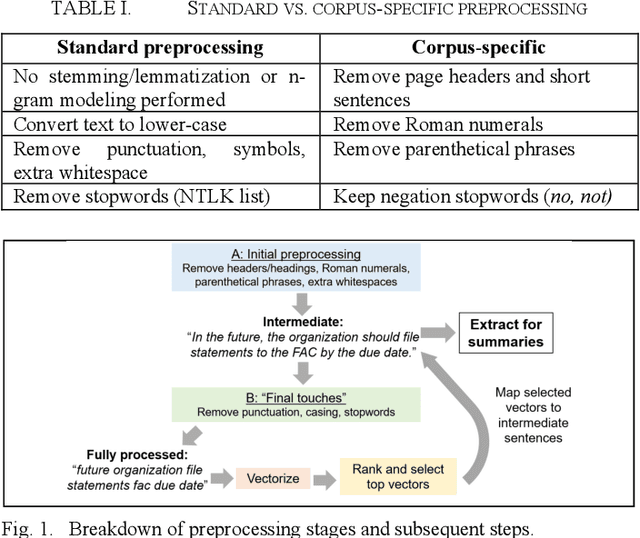

The rapid growth of text data has motivated the development of machine-learning based automatic text summarization strategies that concisely capture the essential ideas in a larger text. This study aimed to devise an extractive summarization method for A-133 Single Audits, which assess if recipients of federal grants are compliant with program requirements for use of federal funding. Currently, these voluminous audits must be manually analyzed by officials for oversight, risk management, and prioritization purposes. Automated summarization has the potential to streamline these processes. Analysis focused on the "Findings" section of ~20,000 Single Audits spanning 2016-2018. Following text preprocessing and GloVe embedding, sentence-level k-means clustering was performed to partition sentences by topic and to establish the importance of each sentence. For each audit, key summary sentences were extracted by proximity to cluster centroids. Summaries were judged by non-expert human evaluation and compared to human-generated summaries using the ROUGE metric. Though the goal was to fully automate summarization of A-133 audits, human input was required at various stages due to large variability in audit writing style, content, and context. Examples of human inputs include the number of clusters, the choice to keep or discard certain clusters based on their content relevance, and the definition of a top sentence. Overall, this approach made progress towards automated extractive summaries of A-133 audits, with future work to focus on full automation and improving summary consistency. This work highlights the inherent difficulty and subjective nature of automated summarization in a real-world application.