 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIGCN: Integrative Graph Convolutional Networks for Multi-modal Data
Feb 04, 2024



Recent advances in Graph Neural Networks (GNN) have led to a considerable growth in graph data modeling for multi-modal data which contains various types of nodes and edges. Although some integrative prediction solutions have been developed recently for network-structured data, these methods have some restrictions. For a node classification task involving multi-modal data, certain data modalities may perform better when predicting one class, while others might excel in predicting a different class. Thus, to obtain a better learning representation, advanced computational methodologies are required for the integrative analysis of multi-modal data. Moreover, existing integrative tools lack a comprehensive and cohesive understanding of the rationale behind their specific predictions, making them unsuitable for enhancing model interpretability. Addressing these restrictions, we introduce a novel integrative neural network approach for multi-modal data networks, named Integrative Graph Convolutional Networks (IGCN). IGCN learns node embeddings from multiple topologies and fuses the multiple node embeddings into a weighted form by assigning attention coefficients to the node embeddings. Our proposed attention mechanism helps identify which types of data receive more emphasis for each sample to predict a certain class. Therefore, IGCN has the potential to unravel previously unknown characteristics within different node classification tasks. We benchmarked IGCN on several datasets from different domains, including a multi-omics dataset to predict cancer subtypes and a multi-modal clinical dataset to predict the progression of Alzheimer's disease. Experimental results show that IGCN outperforms or is on par with the state-of-the-art and baseline methods.
Forecasting Multilinear Data via Transform-Based Tensor Autoregression
May 24, 2022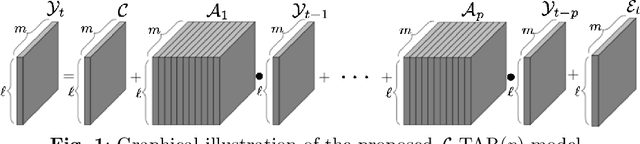
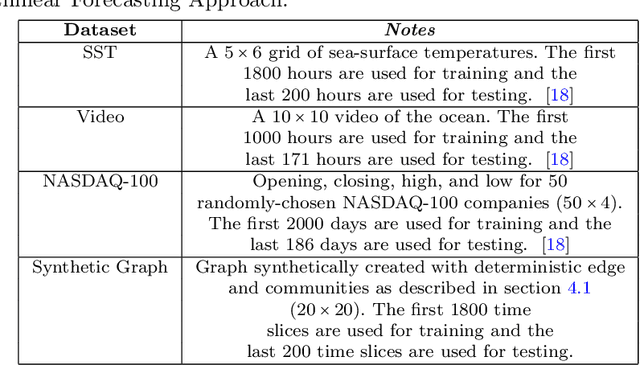
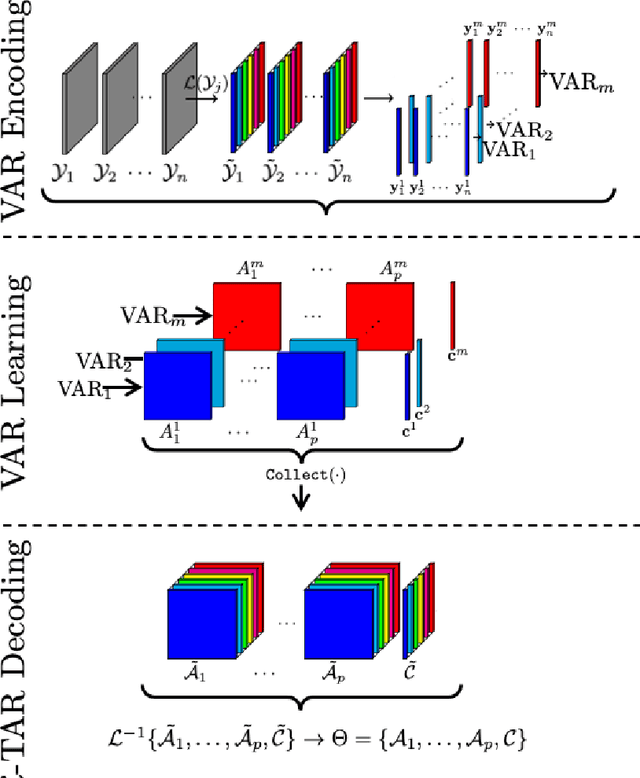

In the era of big data, there is an increasing demand for new methods for analyzing and forecasting 2-dimensional data. The current research aims to accomplish these goals through the combination of time-series modeling and multilinear algebraic systems. We expand previous autoregressive techniques to forecast multilinear data, aptly named the L-Transform Tensor autoregressive (L-TAR for short). Tensor decompositions and multilinear tensor products have allowed for this approach to be a feasible method of forecasting. We achieve statistical independence between the columns of the observations through invertible discrete linear transforms, enabling a divide and conquer approach. We present an experimental validation of the proposed methods on datasets containing image collections, video sequences, sea surface temperature measurements, stock prices, and networks.
High-Order Multilinear Discriminant Analysis via Order-$\textit{n}$ Tensor Eigendecomposition
May 18, 2022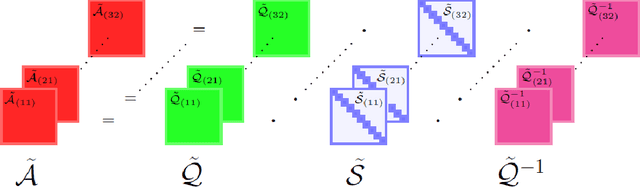


Higher-order data with high dimensionality is of immense importance in many areas of machine learning, computer vision, and video analytics. Multidimensional arrays (commonly referred to as tensors) are used for arranging higher-order data structures while keeping the natural representation of the data samples. In the past decade, great efforts have been made to extend the classic linear discriminant analysis for higher-order data classification generally referred to as multilinear discriminant analysis (MDA). Most of the existing approaches are based on the Tucker decomposition and $\textit{n}$-mode tensor-matrix products. The current paper presents a new approach to tensor-based multilinear discriminant analysis referred to as High-Order Multilinear Discriminant Analysis (HOMLDA). This approach is based upon the tensor decomposition where an order-$\textit{n}$ tensor can be written as a product of order-$\textit{n}$ tensors and has a natural extension to traditional linear discriminant analysis (LDA). Furthermore, the resulting framework, HOMLDA, might produce a within-class scatter tensor that is close to singular. Thus, computing the inverse inaccurately may distort the discriminant analysis. To address this problem, an improved method referred to as Robust High-Order Multilinear Discriminant Analysis (RHOMLDA) is introduced. Experimental results on multiple data sets illustrate that our proposed approach provides improved classification performance with respect to the current Tucker decomposition-based supervised learning methods.