 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking mulitple targets with multiple radars using Distributed Auctions
Jul 31, 2023Coordination of radars can be performed in various ways. To be more resilient radar networks can be coordinated in a decentralized way. In this paper, we introduce a highly resilient algorithm for radar coordination based on decentralized and collaborative bundle auctions. We first formalize our problem as a constrained optimization problem and apply a market-based algorithm to provide an approximate solution. Our approach allows to track simultaneously multiple targets, and to use up to two radars tracking the same target to improve accuracy. We show that our approach performs sensibly as well as a centralized approach relying on a MIP solver, and depending on the situations, may outperform it or be outperformed.
Multi-Radar Tracking Optimization for Collaborative Combat
Oct 20, 2020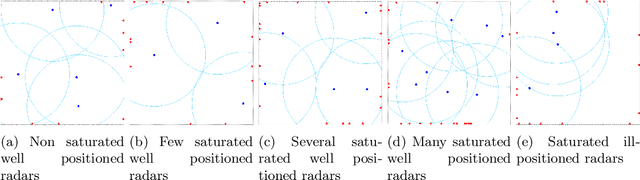
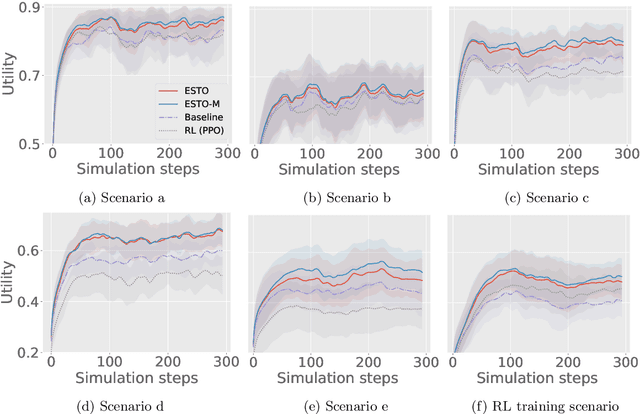
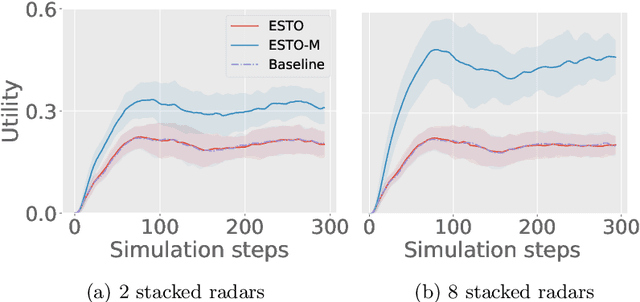
Smart Grids of collaborative netted radars accelerate kill chains through more efficient cross-cueing over centralized command and control. In this paper, we propose two novel reward-based learning approaches to decentralized netted radar coordination based on black-box optimization and Reinforcement Learning (RL). To make the RL approach tractable, we use a simplification of the problem that we proved to be equivalent to the initial formulation. We apply these techniques on a simulation where radars can follow multiple targets at the same time and show they can learn implicit cooperation by comparing them to a greedy baseline.
MCTS-based Automated Negotiation Agent
Sep 12, 2019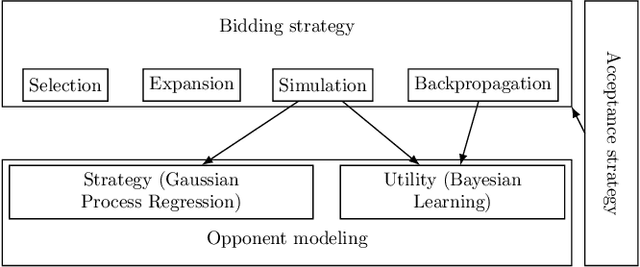
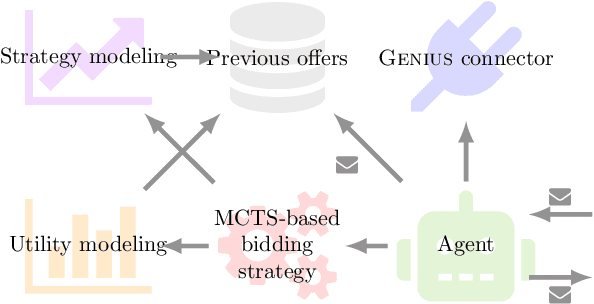
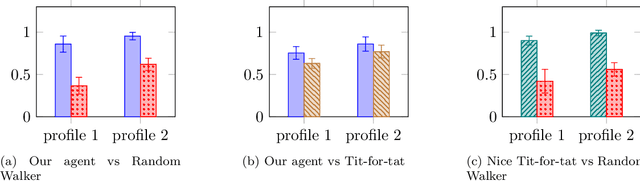
This paper introduces a new negotiating agent model for automated negotiation. We focus on applications without time pressure with multidi-mensional negotiation on both continuous and discrete domains. The agent bidding strategy relies on Monte Carlo Tree Search, which is a trendy method since it has been used with success on games with high branching factor such as Go. It also exploits opponent modeling techniques thanks to Gaussian process regression and Bayesian learning. Evaluation is done by confronting the existing agents that are able to negotiate in such context: Random Walker, Tit-for-tat and Nice Tit-for-Tat. None of those agents succeeds in beating our agent. Also, the modular and adaptive nature of our approach is a huge advantage when it comes to optimize it in specific applicative contexts.
Curiosity-Aware Bargaining
Dec 30, 2016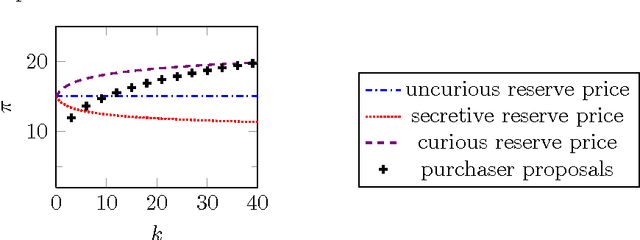
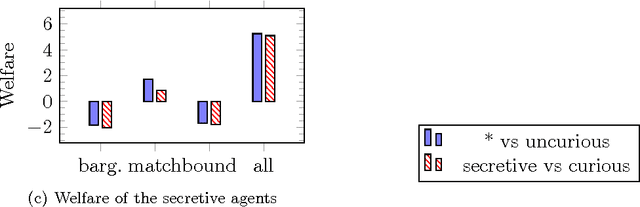
Opponent modeling consists in modeling the strategy or preferences of an agent thanks to the data it provides. In the context of automated negotiation and with machine learning, it can result in an advantage so overwhelming that it may restrain some casual agents to be part of the bargaining process. We qualify as "curious" an agent driven by the desire of negotiating in order to collect information and improve its opponent model. However, neither curiosity-based rational-ity nor curiosity-robust protocol have been studied in automatic negotiation. In this paper, we rely on mechanism design to propose three extensions of the standard bargaining protocol that limit information leak. Those extensions are supported by an enhanced rationality model, that considers the exchanged information. Also, they are theoretically analyzed and experimentally evaluated.