 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFCN+RL: A Fully Convolutional Network followed by Refinement Layers to Offline Handwritten Signature Segmentation
May 28, 2020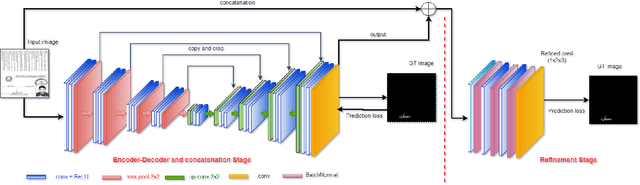

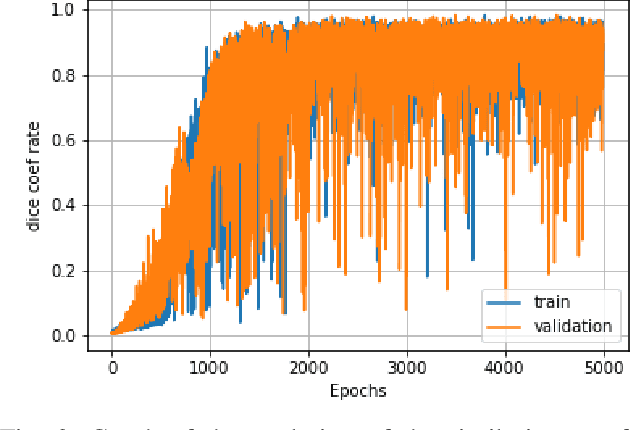

Although secular, handwritten signature is one of the most reliable biometric methods used by most countries. In the last ten years, the application of technology for verification of handwritten signatures has evolved strongly, including forensic aspects. Some factors, such as the complexity of the background and the small size of the region of interest - signature pixels - increase the difficulty of the targeting task. Other factors that make it challenging are the various variations present in handwritten signatures such as location, type of ink, color and type of pen, and the type of stroke. In this work, we propose an approach to locate and extract the pixels of handwritten signatures on identification documents, without any prior information on the location of the signatures. The technique used is based on a fully convolutional encoder-decoder network combined with a block of refinement layers for the alpha channel of the predicted image. The experimental results demonstrate that the technique outputs a clean signature with higher fidelity in the lines than the traditional approaches and preservation of the pertinent characteristics to the signer's spelling. To evaluate the quality of our proposal, we use the following image similarity metrics: SSIM, SIFT, and Dice Coefficient. The qualitative and quantitative results show a significant improvement in comparison with the baseline system.
A Fast Fully Octave Convolutional Neural Network for Document Image Segmentation
Apr 03, 2020



The Know Your Customer (KYC) and Anti Money Laundering (AML) are worldwide practices to online customer identification based on personal identification documents, similarity and liveness checking, and proof of address. To answer the basic regulation question: are you whom you say you are? The customer needs to upload valid identification documents (ID). This task imposes some computational challenges since these documents are diverse, may present different and complex backgrounds, some occlusion, partial rotation, poor quality, or damage. Advanced text and document segmentation algorithms were used to process the ID images. In this context, we investigated a method based on U-Net to detect the document edges and text regions in ID images. Besides the promising results on image segmentation, the U-Net based approach is computationally expensive for a real application, since the image segmentation is a customer device task. We propose a model optimization based on Octave Convolutions to qualify the method to situations where storage, processing, and time resources are limited, such as in mobile and robotic applications. We conducted the evaluation experiments in two new datasets CDPhotoDataset and DTDDataset, which are composed of real ID images of Brazilian documents. Our results showed that the proposed models are efficient to document segmentation tasks and portable.
* This paper was accepted for IJCNN 2020 Conference