 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecasting Monthly Residential Natural Gas Demand Using Just-In-Time-Learning Modeling
Feb 28, 2025Natural gas (NG) is relatively a clean source of energy, particularly compared to fossil fuels, and worldwide consumption of NG has been increasing almost linearly in the last two decades. A similar trend can also be seen in Turkey, while another similarity is the high dependence on imports for the continuous NG supply. It is crucial to accurately forecast future NG demand (NGD) in Turkey, especially, for import contracts; in this respect, forecasts of monthly NGD for the following year are of utmost importance. In the current study, the historical monthly NG consumption data between 2014 and 2024 provided by SOCAR, the local residential NG distribution company for two cities in Turkey, Bursa and Kayseri, was used to determine out-of-sample monthly NGD forecasts for a period of one year and nine months using various time series models, including SARIMA and ETS models, and a novel proposed machine learning method. The proposed method, named Just-in-Time-Learning-Gaussian Process Regression (JITL-GPR), uses a novel feature representation for the past NG demand values; instead of using past demand values as column-wise separate features, they are placed on a two-dimensional (2-D) grid of year-month values. For each test point, a kernel function, tailored for the NGD predictions, is used in GPR to predict the query point. Since a model is constructed separately for each test point, the proposed method is, indeed, an example of JITL. The JITL-GPR method is easy to use and optimize, and offers a reduction in forecast errors compared to traditional time series methods and a state-of-the-art combination model; therefore, it is a promising tool for NGD forecasting in similar settings.
Semi-supervised Variational Autoencoder for Regression: Application on Soft Sensors
Nov 17, 2022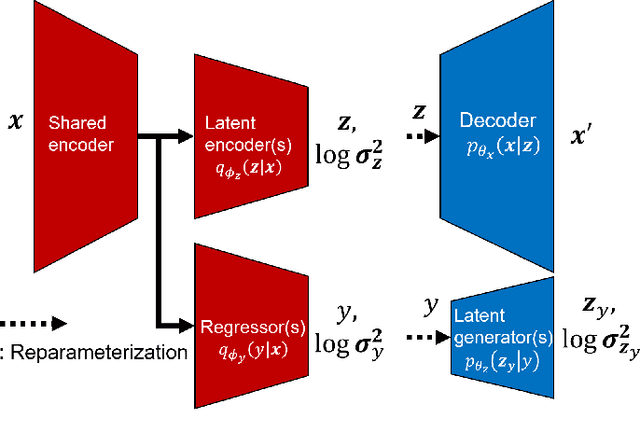

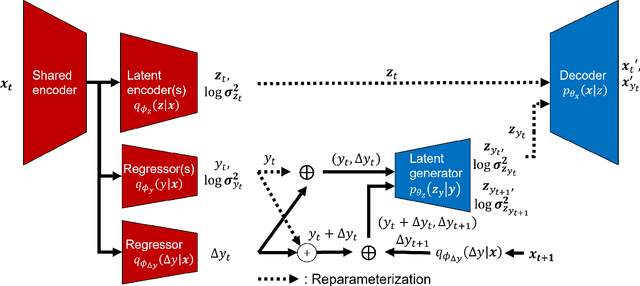

We present the development of a semi-supervised regression method using variational autoencoders (VAE), which is customized for use in soft sensing applications. We motivate the use of semi-supervised learning considering the fact that process quality variables are not collected at the same frequency as other process variables leading to many unlabelled records in operational datasets. These unlabelled records are not possible to use for training quality variable predictions based on supervised learning methods. Use of VAEs for unsupervised learning is well established and recently they were used for regression applications based on variational inference procedures. We extend this approach of supervised VAEs for regression (SVAER) to make it learn from unlabelled data leading to semi-supervised VAEs for regression (SSVAER), then we make further modifications to their architecture using additional regularization components to make SSVAER well suited for learning from both labelled and unlabelled process data. The probabilistic regressor resulting from the variational approach makes it possible to estimate the variance of the predictions simultaneously, which provides an uncertainty quantification along with the generated predictions. We provide an extensive comparative study of SSVAER with other publicly available semi-supervised and supervised learning methods on two benchmark problems using fixed-size datasets, where we vary the percentage of labelled data available for training. In these experiments, SSVAER achieves the lowest test errors in 11 of the 20 studied cases, compared to other methods where the second best gets 4 lowest test errors out of the 20.
An Exploratory Analysis of Biased Learners in Soft-Sensing Frames
Apr 24, 2019
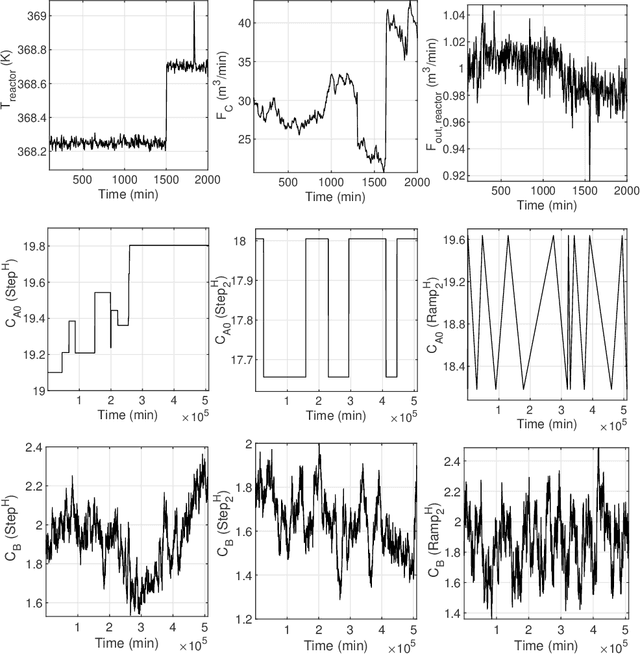

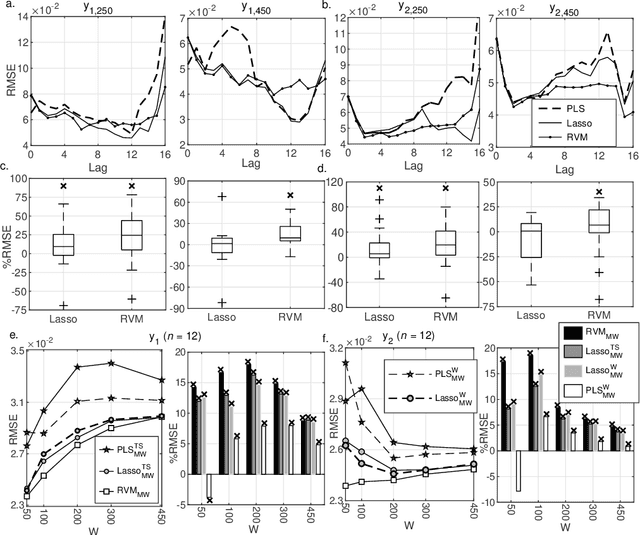
Data driven soft sensor design has recently gained immense popularity, due to advances in sensory devices, and a growing interest in data mining. While partial least squares (PLS) is traditionally used in the process literature for designing soft sensors, the statistical literature has focused on sparse learners, such as Lasso and relevance vector machine (RVM), to solve the high dimensional data problem. In the current study, predictive performances of three regression techniques, PLS, Lasso and RVM were assessed and compared under various offline and online soft sensing scenarios applied on datasets from five real industrial plants, and a simulated process. In offline learning, predictions of RVM and Lasso were found to be superior to those of PLS when a large number of time-lagged predictors were used. Online prediction results gave a slightly more complicated picture. It was found that the minimum prediction error achieved by PLS under moving window (MW), or just-in-time learning scheme was decreased up to ~5-10% using Lasso, or RVM. However, when a small MW size was used, or the optimum number of PLS components was as low as ~1, prediction performance of PLS surpassed RVM, which was found to yield occasional unstable predictions. PLS and Lasso models constructed via online parameter tuning generally did not yield better predictions compared to those constructed via offline tuning. We present evidence to suggest that retaining a large portion of the available process measurement data in the predictor matrix, instead of preselecting variables, would be more advantageous for sparse learners in increasing prediction accuracy. As a result, Lasso is recommended as a better substitute for PLS in soft sensors; while performance of RVM should be validated before online application.