Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVolume-preserving Neural Networks: A Solution to the Vanishing Gradient Problem
Nov 22, 2019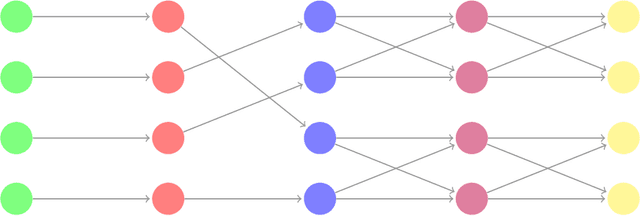
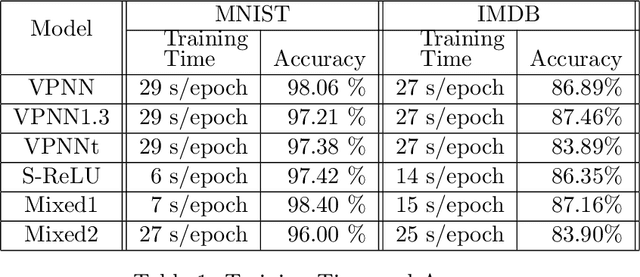
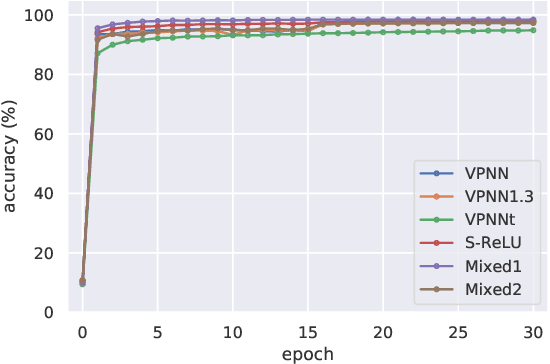
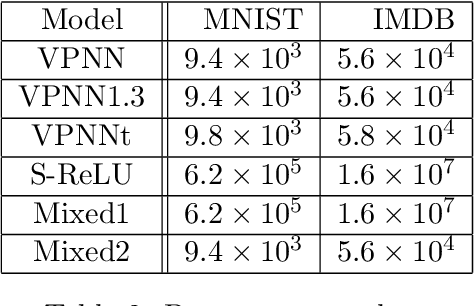
We propose a novel approach to addressing the vanishing (or exploding) gradient problem in deep neural networks. We construct a new architecture for deep neural networks where all layers (except the output layer) of the network are a combination of rotation, permutation, diagonal, and activation sublayers which are all volume preserving. This control on the volume forces the gradient (on average) to maintain equilibrium and not explode or vanish. Volume-preserving neural networks train reliably, quickly and accurately and the learning rate is consistent across layers in deep volume-preserving neural networks. To demonstrate this we apply our volume-preserving neural network model to two standard datasets.
* 20 pages, 8 figures
Via