 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCognitively-Inspired Tokens Overcome Egocentric Bias in Multimodal Models
Jan 23, 2026Multimodal language models (MLMs) perform well on semantic vision-language tasks but fail at spatial reasoning that requires adopting another agent's visual perspective. These errors reflect a persistent egocentric bias and raise questions about whether current models support allocentric reasoning. Inspired by human spatial cognition, we introduce perspective tokens, specialized embeddings that encode orientation through either (1) embodied body-keypoint cues or (2) abstract representations supporting mental rotation. Integrating these tokens into LLaVA-1.5-13B yields performance on level-2 visual perspective-taking tasks. Across synthetic and naturalistic benchmarks (Isle Bricks V2, COCO, 3DSRBench), perspective tokens improve accuracy, with rotation-based tokens generalizing to non-human reference agents. Representational analyses reveal that fine-tuning enhances latent orientation sensitivity already present in the base model, suggesting that MLMs contain precursors of allocentric reasoning but lack appropriate internal structure. Overall, embedding cognitively grounded spatial structure directly into token space provides a lightweight, model-agnostic mechanism for perspective-taking and more human-like spatial reasoning.
Failures in Perspective-taking of Multimodal AI Systems
Sep 20, 2024
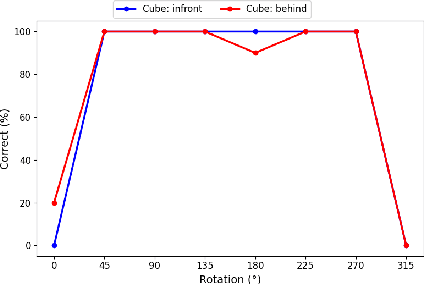
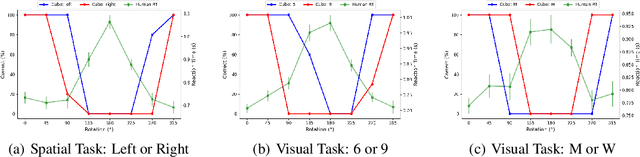
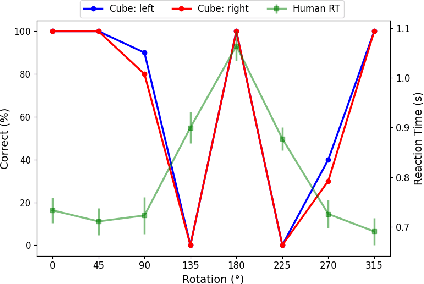
This study extends previous research on spatial representations in multimodal AI systems. Although current models demonstrate a rich understanding of spatial information from images, this information is rooted in propositional representations, which differ from the analog representations employed in human and animal spatial cognition. To further explore these limitations, we apply techniques from cognitive and developmental science to assess the perspective-taking abilities of GPT-4o. Our analysis enables a comparison between the cognitive development of the human brain and that of multimodal AI, offering guidance for future research and model development.