 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Artificial Intelligence Browser Architecture (AIBA) For Our Kind and Others: A Voice Name System Speech implementation with two warrants, Wake Neutrality and Value Preservation of Personally Identifiable Information
Apr 01, 2022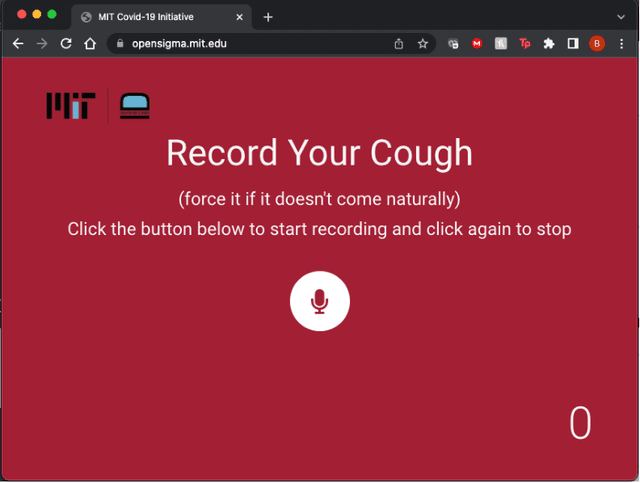
Conversational commerce, first pioneered by Apple's Siri, is the first of may applications based on always-on artificial intelligence systems that decide on its own when to interact with the environment, potentially collecting 24x7 longitudinal training data that is often Personally Identifiable Information (PII). A large body of scholarly papers, on the order of a million according to a simple Google Scholar search, suggests that the treatment of many health conditions, including COVID-19 and dementia, can be vastly improved by this data if the dataset is large enough as it has happened in other domains (e.g. GPT3). In contrast, current dominant systems are closed garden solutions without wake neutrality and that can't fully exploit the PII data they have because of IRB and Cohues-type constraints. We present a voice browser-and-server architecture that aims to address these two limitations by offering wake neutrality and the possibility to handle PII aiming to maximize its value. We have implemented this browser for the collection of speech samples and have successfully demonstrated it can capture over 200.000 samples of COVID-19 coughs. The architecture we propose is designed so it can grow beyond our kind into other domains such as collecting sound samples from vehicles, video images from nature, ingestible robotics, multi-modal signals (EEG, EKG,...), or even interacting with other kinds such as dogs and cats.
Longitudinal Speech Biomarkers for Automated Alzheimer's Detection
Nov 22, 2021

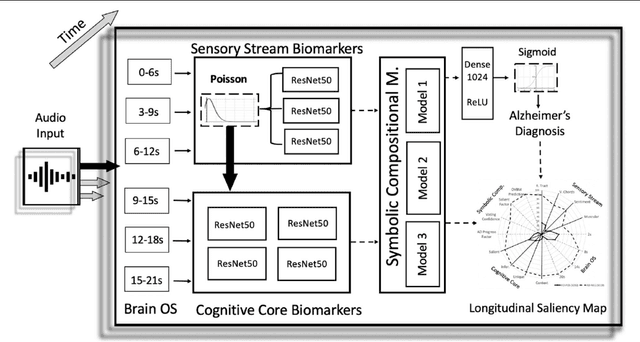
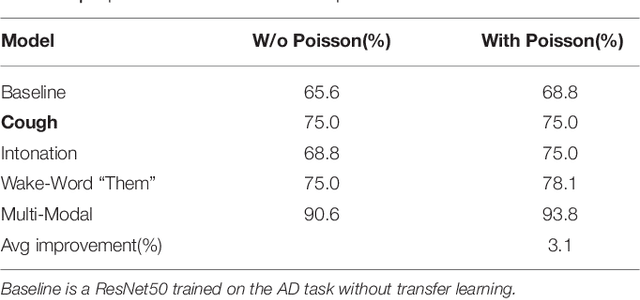
We introduce a novel audio processing architecture, the Open Voice Brain Model (OVBM), improving detection accuracy for Alzheimer's (AD) longitudinal discrimination from spontaneous speech. We also outline the OVBM design methodology leading us to such architecture, which in general can incorporate multimodal biomarkers and target simultaneously several diseases and other AI tasks. Key in our methodology is the use of multiple biomarkers complementing each other, and when two of them uniquely identify different subjects in a target disease we say they are orthogonal. We illustrate the methodology by introducing 16 biomarkers, three of which are orthogonal, demonstrating simultaneous above state-of-the-art discrimination for apparently unrelated diseases such as AD and COVID-19. Inspired by research conducted at the MIT Center for Brain Minds and Machines, OVBM combines biomarker implementations of the four modules of intelligence: The brain OS chunks and overlaps audio samples and aggregates biomarker features from the sensory stream and cognitive core creating a multi-modal graph neural network of symbolic compositional models for the target task. We apply it to AD, achieving above state-of-the-art accuracy of 93.8% on raw audio, while extracting a subject saliency map that longitudinally tracks relative disease progression using multiple biomarkers, 16 in the reported AD task. The ultimate aim is to help medical practice by detecting onset and treatment impact so that intervention options can be longitudinally tested. Using the OBVM design methodology, we introduce a novel lung and respiratory tract biomarker created using 200,000+ cough samples to pre-train a model discriminating cough cultural origin. This cough dataset sets a new benchmark as the largest audio health dataset with 30,000+ subjects participating in April 2020, demonstrating for the first-time cough cultural bias.
Hi Sigma, do I have the Coronavirus?: Call for a New Artificial Intelligence Approach to Support Health Care Professionals Dealing With The COVID-19 Pandemic
Apr 10, 2020
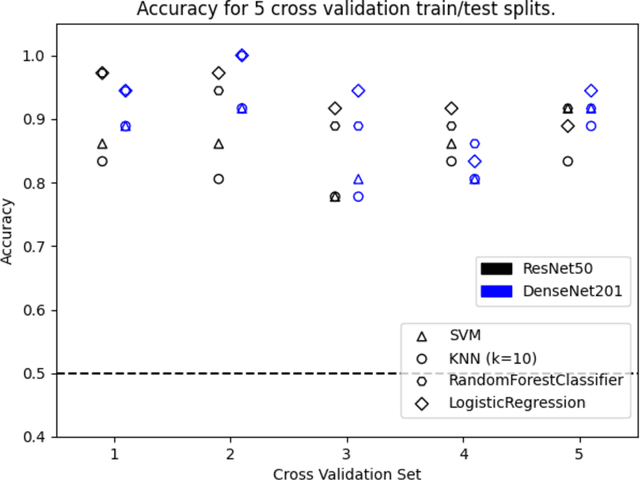

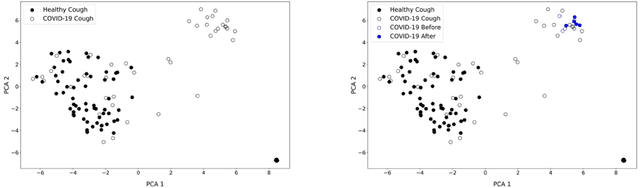
Just like your phone can detect what song is playing in crowded spaces, we show that Artificial Intelligence transfer learning algorithms trained on cough phone recordings results in diagnostic tests for COVID-19. To gain adoption by the health care community, we plan to validate our results in a clinical trial and three other venues in Mexico, Spain and the USA . However, if we had data from other on-going clinical trials and volunteers, we may do much more. For example, for confirmed stay-at-home COVID-19 patients, a longitudinal audio test could be developed to determine contact-with-hospital recommendations, and for the most critical COVID-19 patients a success ratio forecast test, including patient clinical data, to prioritize ICU allocation. As a challenge to the engineering community and in the context of our clinical trial, the authors suggest distributing cough recordings daily, hoping other trials and crowdsourcing users will contribute more data. Previous approaches to complex AI tasks have either used a static dataset or were private efforts led by large corporations. All existing COVID-19 trials published also follow this paradigm. Instead, we suggest a novel open collective approach to large-scale real-time health care AI. We will be posting updates at https://opensigma.mit.edu. Our personal view is that our approach is the right one for large scale pandemics, and therefore is here to stay - will you join?