Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent Probing Interaction Policies
Dec 13, 2019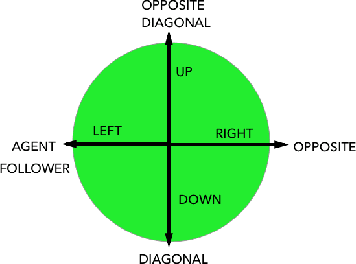
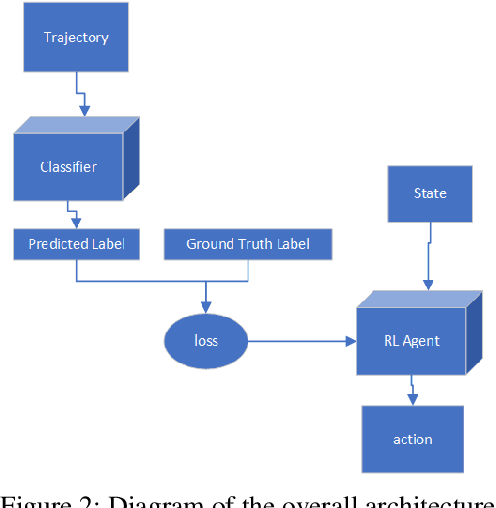
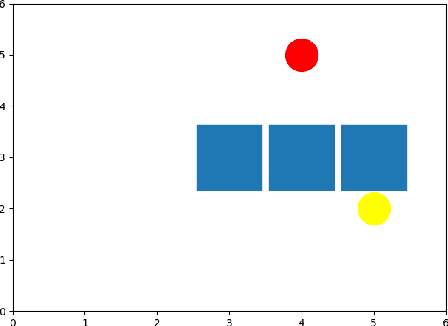
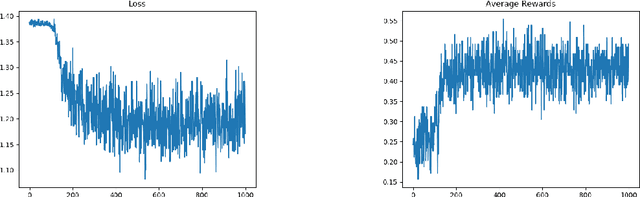
Reinforcement learning in a multi agent system is difficult because these systems are inherently non-stationary in nature. In such a case, identifying the type of the opposite agent is crucial and can help us address this non-stationary environment. We have investigated if we can employ some probing policies which help us better identify the type of the other agent in the environment. We've made a simplifying assumption that the other agent has a stationary policy that our probing policy is trying to approximate. Our work extends Environmental Probing Interaction Policy framework to handle multi agent environments.
Via