 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCATGNN: Cost-Efficient and Scalable Distributed Training for Graph Neural Networks
Apr 02, 2024Graph neural networks have been shown successful in recent years. While different GNN architectures and training systems have been developed, GNN training on large-scale real-world graphs still remains challenging. Existing distributed systems load the entire graph in memory for graph partitioning, requiring a huge memory space to process large graphs and thus hindering GNN training on such large graphs using commodity workstations. In this paper, we propose CATGNN, a cost-efficient and scalable distributed GNN training system which focuses on scaling GNN training to billion-scale or larger graphs under limited computational resources. Among other features, it takes a stream of edges as input, instead of loading the entire graph in memory, for partitioning. We also propose a novel streaming partitioning algorithm named SPRING for distributed GNN training. We verify the correctness and effectiveness of CATGNN with SPRING on 16 open datasets. In particular, we demonstrate that CATGNN can handle the largest publicly available dataset with limited memory, which would have been infeasible without increasing the memory space. SPRING also outperforms state-of-the-art partitioning algorithms significantly, with a 50% reduction in replication factor on average.
Characterizing the Efficiency of Graph Neural Network Frameworks with a Magnifying Glass
Nov 06, 2022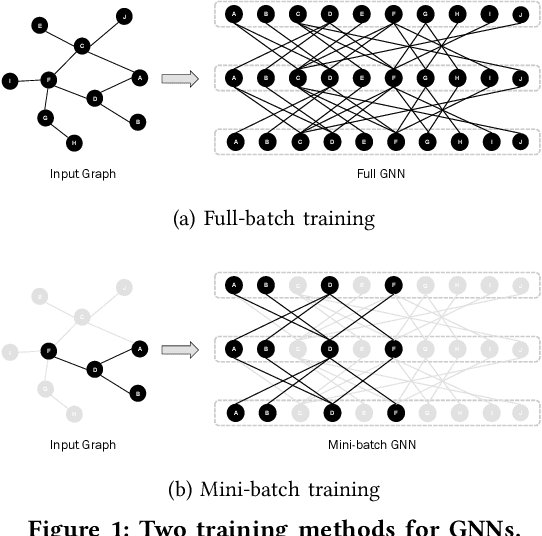
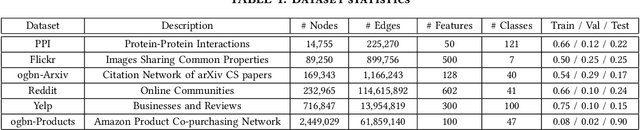
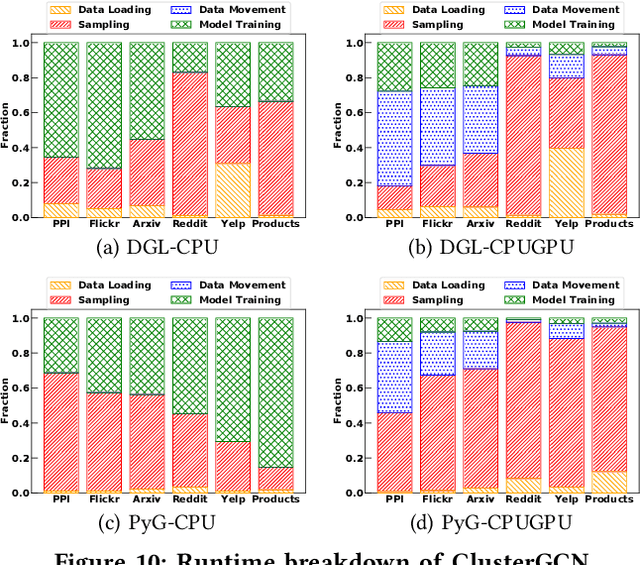
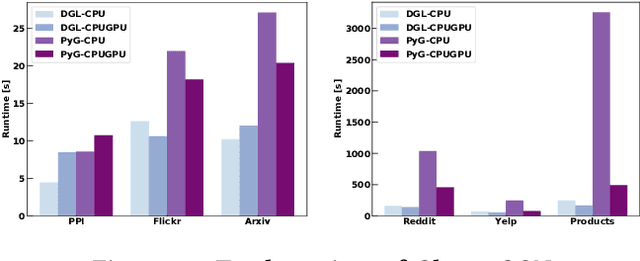
Graph neural networks (GNNs) have received great attention due to their success in various graph-related learning tasks. Several GNN frameworks have then been developed for fast and easy implementation of GNN models. Despite their popularity, they are not well documented, and their implementations and system performance have not been well understood. In particular, unlike the traditional GNNs that are trained based on the entire graph in a full-batch manner, recent GNNs have been developed with different graph sampling techniques for mini-batch training of GNNs on large graphs. While they improve the scalability, their training times still depend on the implementations in the frameworks as sampling and its associated operations can introduce non-negligible overhead and computational cost. In addition, it is unknown how much the frameworks are 'eco-friendly' from a green computing perspective. In this paper, we provide an in-depth study of two mainstream GNN frameworks along with three state-of-the-art GNNs to analyze their performance in terms of runtime and power/energy consumption. We conduct extensive benchmark experiments at several different levels and present detailed analysis results and observations, which could be helpful for further improvement and optimization.