 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Cloud Data Simulation and Modelling with Aize Workspace
Jan 19, 2023This work takes a look at data models often used in digital twins and presents preliminary results specifically from surface reconstruction and semantic segmentation models trained using simulated data. This work is expected to serve as a ground work for future endeavours in data contextualisation inside a digital twin.
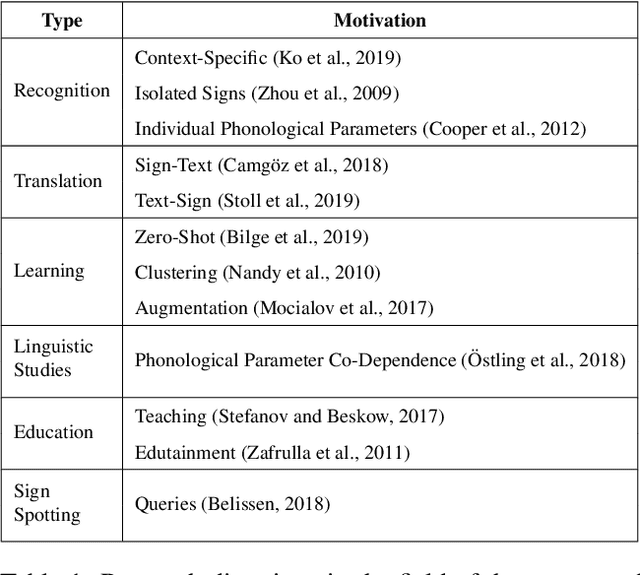
Classification of Phonological Parameters in Sign Languages
May 24, 2022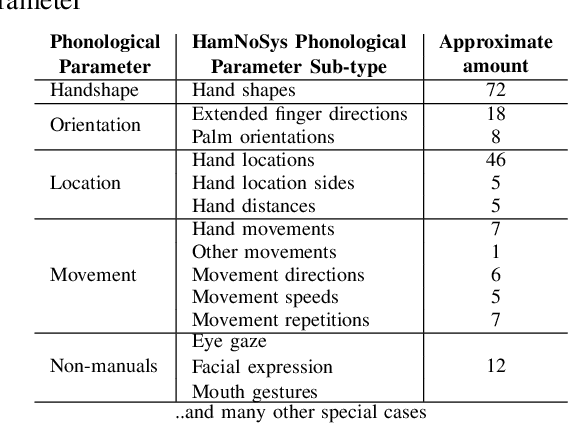

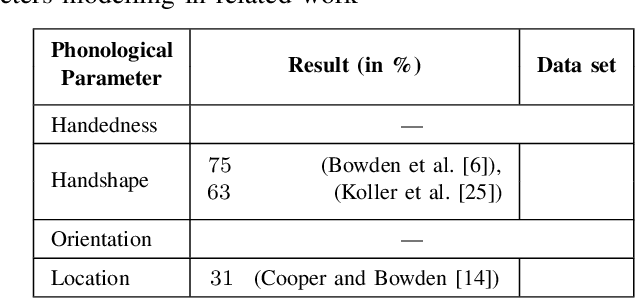
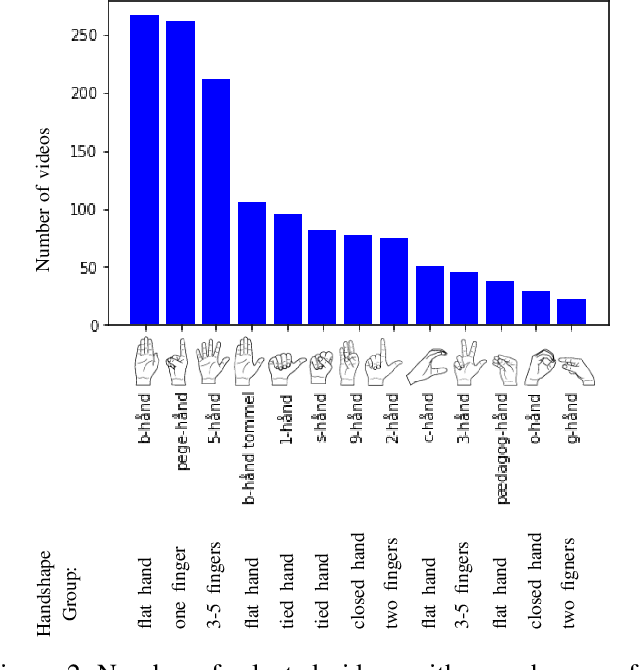
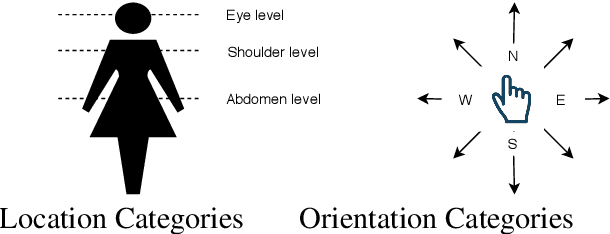
Signers compose sign language phonemes that enable communication by combining phonological parameters such as handshape, orientation, location, movement, and non-manual features. Linguistic research often breaks down signs into their constituent parts to study sign languages and often a lot of effort is invested into the annotation of the videos. In this work we show how a single model can be used to recognise the individual phonological parameters within sign languages with the aim of either to assist linguistic annotations or to describe the signs for the sign recognition models. We use Danish Sign Language data set `Ordbog over Dansk Tegnsprog' to generate multiple data sets using pose estimation model, which are then used for training the multi-label Fast R-CNN model to support multi-label modelling. Moreover, we show that there is a significant co-dependence between the orientation and location phonological parameters in the generated data and we incorporate this co-dependence in the model to achieve better performance.
Unsupervised Sign Language Phoneme Clustering using HamNoSys Notation
May 21, 2022

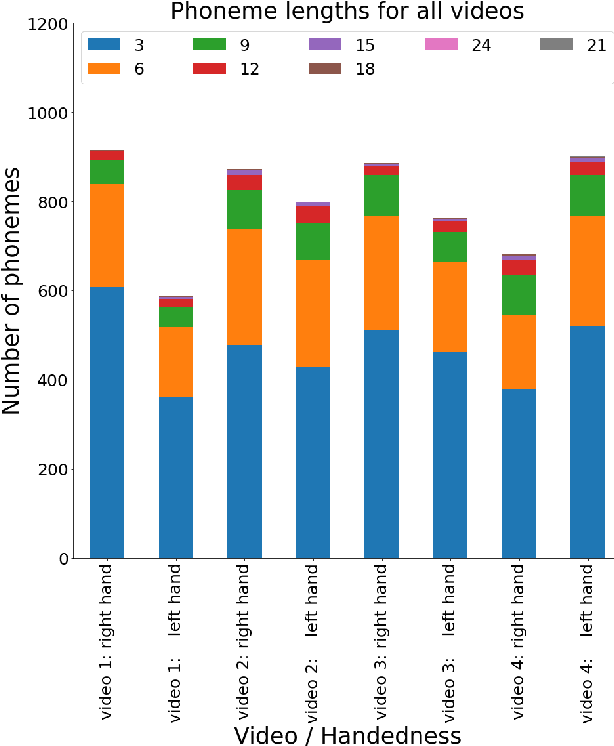
Traditionally, sign language resources have been collected in controlled settings for specific tasks involving supervised sign classification or linguistic studies accompanied by specific annotation type. To date, very few who explored signing videos found online on social media platforms as well as the use of unsupervised methods applied to such resources. Due to the fact that the field is striving to achieve acceptable model performance on the data that differs from that seen during training calls for more diversity in sign language data, stepping away from the data obtained in controlled laboratory settings. Moreover, since the sign language data collection and annotation carries large overheads, it is desirable to accelerate the annotation process. Considering the aforementioned tendencies, this paper takes the side of harvesting online data in a pursuit for automatically generating and annotating sign language corpora through phoneme clustering.
Transfer Learning for British Sign Language Modelling
Jun 03, 2020
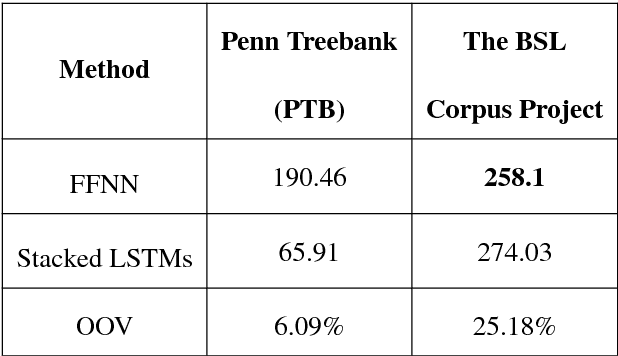

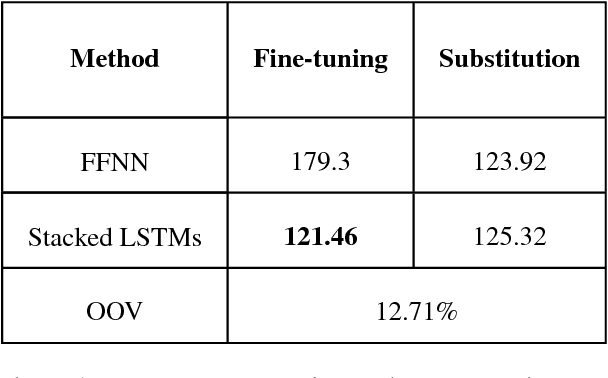
Automatic speech recognition and spoken dialogue systems have made great advances through the use of deep machine learning methods. This is partly due to greater computing power but also through the large amount of data available in common languages, such as English. Conversely, research in minority languages, including sign languages, is hampered by the severe lack of data. This has led to work on transfer learning methods, whereby a model developed for one language is reused as the starting point for a model on a second language, which is less resourced. In this paper, we examine two transfer learning techniques of fine-tuning and layer substitution for language modelling of British Sign Language. Our results show improvement in perplexity when using transfer learning with standard stacked LSTM models, trained initially using a large corpus for standard English from the Penn Treebank corpus
* 10 pages, 3 figures
Towards Large-Scale Data Mining for Data-Driven Analysis of Sign Languages
Jun 03, 2020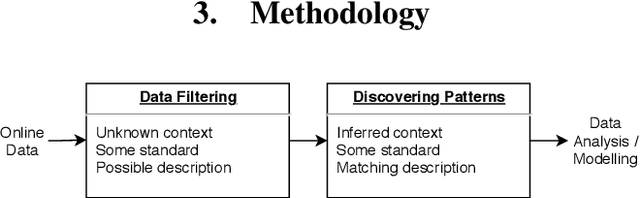

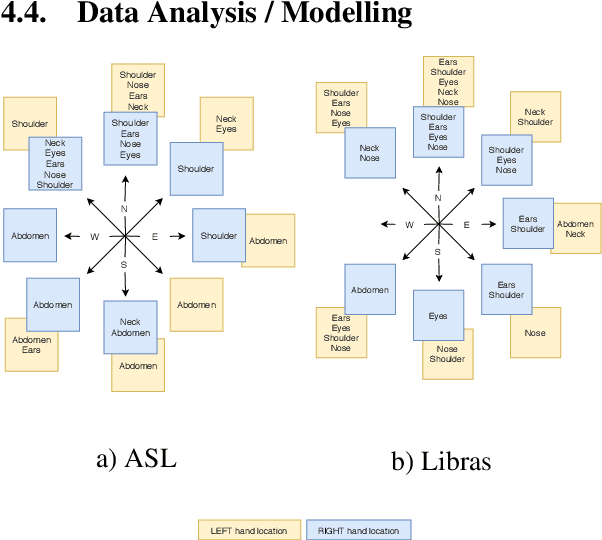
Access to sign language data is far from adequate. We show that it is possible to collect the data from social networking services such as TikTok, Instagram, and YouTube by applying data filtering to enforce quality standards and by discovering patterns in the filtered data, making it easier to analyse and model. Using our data collection pipeline, we collect and examine the interpretation of songs in both the American Sign Language (ASL) and the Brazilian Sign Language (Libras). We explore their differences and similarities by looking at the co-dependence of the orientation and location phonological parameters
* https://colab.research.google.com/drive/118Sx1ua-NXy9kjqWi94vz-RrRVYKmnDl?usp=sharing