 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorr2Distrib: Making Ambiguous Correspondences an Ally to Predict Reliable 6D Pose Distributions
May 05, 2025We introduce Corr2Distrib, the first correspondence-based method which estimates a 6D camera pose distribution from an RGB image, explaining the observations. Indeed, symmetries and occlusions introduce visual ambiguities, leading to multiple valid poses. While a few recent methods tackle this problem, they do not rely on local correspondences which, according to the BOP Challenge, are currently the most effective way to estimate a single 6DoF pose solution. Using correspondences to estimate a pose distribution is not straightforward, since ambiguous correspondences induced by visual ambiguities drastically decrease the performance of PnP. With Corr2Distrib, we turn these ambiguities into an advantage to recover all valid poses. Corr2Distrib first learns a symmetry-aware representation for each 3D point on the object's surface, characterized by a descriptor and a local frame. This representation enables the generation of 3DoF rotation hypotheses from single 2D-3D correspondences. Next, we refine these hypotheses into a 6DoF pose distribution using PnP and pose scoring. Our experimental evaluations on complex non-synthetic scenes show that Corr2Distrib outperforms state-of-the-art solutions for both pose distribution estimation and single pose estimation from an RGB image, demonstrating the potential of correspondences-based approaches.
BOP-D: Revisiting 6D Pose Estimation Benchmark for Better Evaluation under Visual Ambiguities
Aug 30, 2024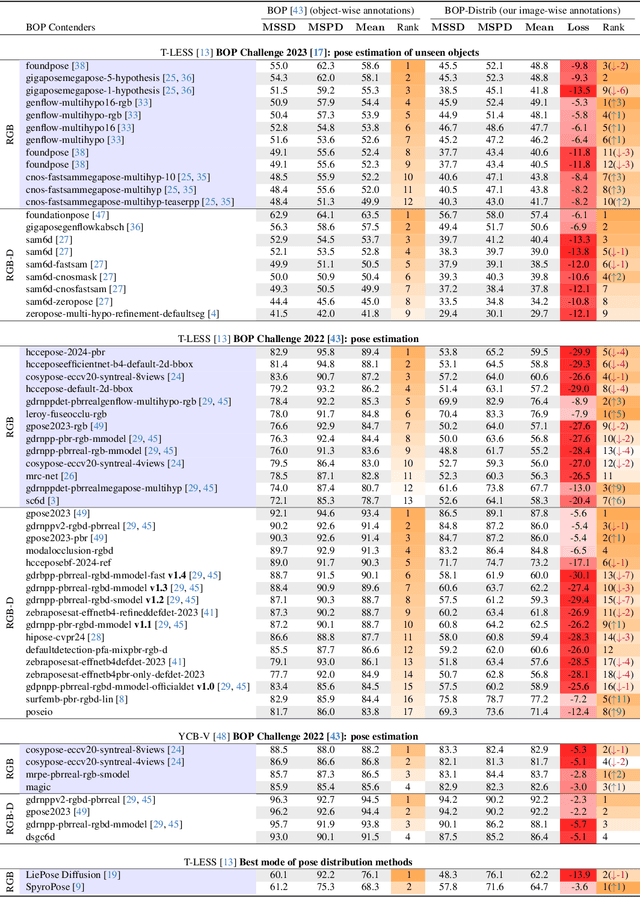
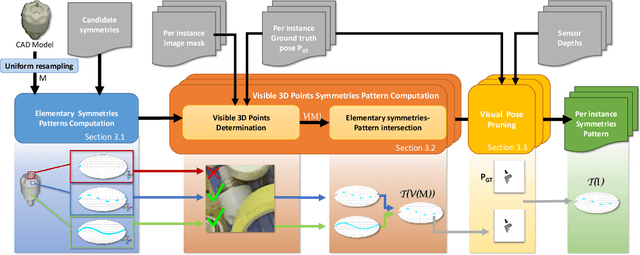
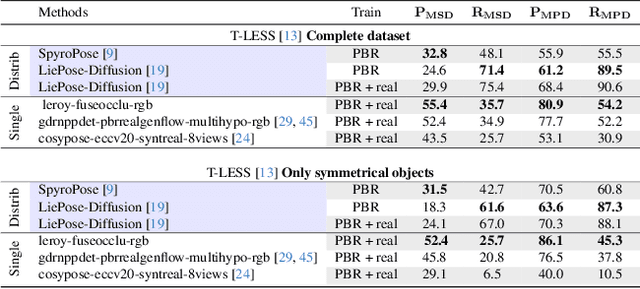

Currently, 6D pose estimation methods are benchmarked on datasets that consider, for their ground truth annotations, visual ambiguities as only related to global object symmetries. However, as previously observed [26], visual ambiguities can also happen depending on the viewpoint or the presence of occluding objects, when disambiguating parts become hidden. The visual ambiguities are therefore actually different across images. We thus first propose an automatic method to re-annotate those datasets with a 6D pose distribution specific to each image, taking into account the visibility of the object surface in the image to correctly determine the visual ambiguities. Given this improved ground truth, we re-evaluate the state-of-the-art methods and show this greatly modify the ranking of these methods. Our annotations also allow us to benchmark recent methods able to estimate a pose distribution on real images for the first time. We will make our annotations for the T-LESS dataset and our code publicly available.