 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOcclusion Guided Self-supervised Scene Flow Estimation on 3D Point Clouds
Apr 10, 2021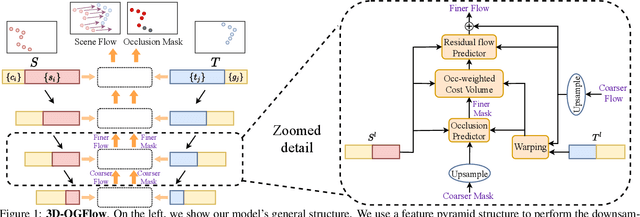



Understanding the flow in 3D space of sparsely sampled points between two consecutive time frames is the core stone of modern geometric-driven systems such as VR/AR, Robotics, and Autonomous driving. The lack of real, non-simulated, labeled data for this task emphasizes the importance of self- or un-supervised deep architectures. This work presents a new self-supervised training method and an architecture for the 3D scene flow estimation under occlusions. Here we show that smart multi-layer fusion between flow prediction and occlusion detection outperforms traditional architectures by a large margin for occluded and non-occluded scenarios. We report state-of-the-art results on Flyingthings3D and KITTI datasets for both the supervised and self-supervised training.
Occlusion Guided Scene Flow Estimation on 3D Point Clouds
Nov 30, 2020
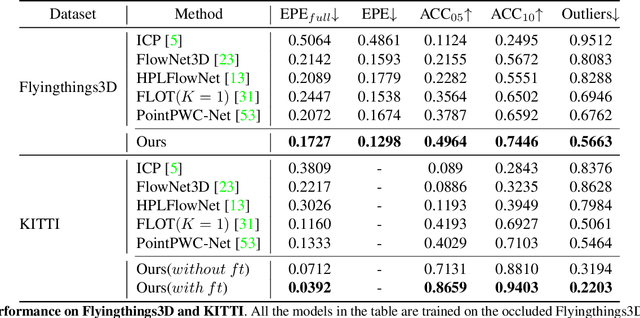


3D scene flow estimation is a vital tool in perceiving our environment given depth or range sensors. Unlike optical flow, the data is usually sparse and in most cases partially occluded in between two temporal samplings. Here we propose a new scene flow architecture called OGSF-Net which tightly couples the learning for both flow and occlusions between frames. Their coupled symbiosis results in a more accurate prediction of flow in space. Unlike a traditional multi-action network, our unified approach is fused throughout the network, boosting performances for both occlusion detection and flow estimation. Our architecture is the first to gauge the occlusion in 3D scene flow estimation on point clouds. In key datasets such as Flyingthings3D and KITTI, we achieve the state-of-the-art results.