 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning for Medical Image Segmentation with Imprecise Annotation
Feb 11, 2024Medical image segmentation (MIS) plays an instrumental role in medical image analysis, where considerable efforts have been devoted to automating the process. Currently, mainstream MIS approaches are based on deep neural networks (DNNs) which are typically trained on a dataset that contains annotation masks produced by doctors. However, in the medical domain, the annotation masks generated by different doctors can inherently vary because a doctor may unnecessarily produce precise and unique annotations to meet the goal of diagnosis. Therefore, the DNN model trained on the data annotated by certain doctors, often just a single doctor, could undesirably favour those doctors who annotate the training data, leading to the unsatisfaction of a new doctor who will use the trained model. To address this issue, this work investigates the utilization of multi-expert annotation to enhance the adaptability of the model to a new doctor and we conduct a pilot study on the MRI brain segmentation task. Experimental results demonstrate that the model trained on a dataset with multi-expert annotation can efficiently cater for a new doctor, after lightweight fine-tuning on just a few annotations from the new doctor.
Two-Stage Multi-task Self-Supervised Learning for Medical Image Segmentation
Feb 11, 2024Medical image segmentation has been significantly advanced by deep learning (DL) techniques, though the data scarcity inherent in medical applications poses a great challenge to DL-based segmentation methods. Self-supervised learning offers a solution by creating auxiliary learning tasks from the available dataset and then leveraging the knowledge acquired from solving auxiliary tasks to help better solve the target segmentation task. Different auxiliary tasks may have different properties and thus can help the target task to different extents. It is desired to leverage their complementary advantages to enhance the overall assistance to the target task. To achieve this, existing methods often adopt a joint training paradigm, which co-solves segmentation and auxiliary tasks by integrating their losses or intermediate gradients. However, direct coupling of losses or intermediate gradients risks undesirable interference because the knowledge acquired from solving each auxiliary task at every training step may not always benefit the target task. To address this issue, we propose a two-stage training approach. In the first stage, the target segmentation task will be independently co-solved with each auxiliary task in both joint training and pre-training modes, with the better model selected via validation performance. In the second stage, the models obtained with respect to each auxiliary task are converted into a single model using an ensemble knowledge distillation method. Our approach allows for making best use of each auxiliary task to create multiple elite segmentation models and then combine them into an even more powerful model. We employed five auxiliary tasks of different proprieties in our approach and applied it to train the U-Net model on an X-ray pneumothorax segmentation dataset. Experimental results demonstrate the superiority of our approach over several existing methods.
A General Multiple Data Augmentation Based Framework for Training Deep Neural Networks
May 29, 2022

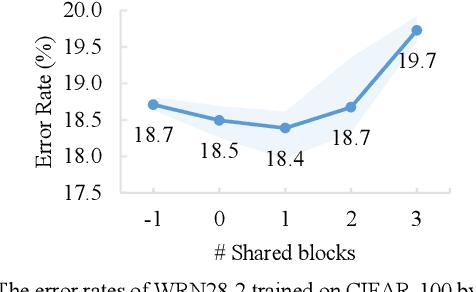
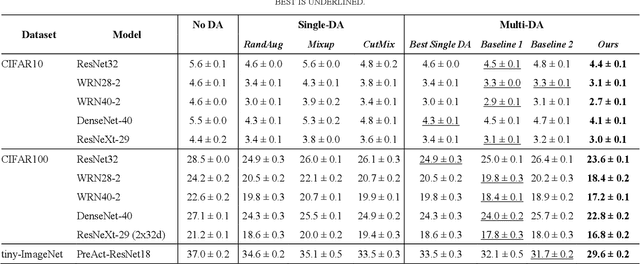
Deep neural networks (DNNs) often rely on massive labelled data for training, which is inaccessible in many applications. Data augmentation (DA) tackles data scarcity by creating new labelled data from available ones. Different DA methods have different mechanisms and therefore using their generated labelled data for DNN training may help improving DNN's generalisation to different degrees. Combining multiple DA methods, namely multi-DA, for DNN training, provides a way to boost generalisation. Among existing multi-DA based DNN training methods, those relying on knowledge distillation (KD) have received great attention. They leverage knowledge transfer to utilise the labelled data sets created by multiple DA methods instead of directly combining them for training DNNs. However, existing KD-based methods can only utilise certain types of DA methods, incapable of utilising the advantages of arbitrary DA methods. We propose a general multi-DA based DNN training framework capable to use arbitrary DA methods. To train a DNN, our framework replicates a certain portion in the latter part of the DNN into multiple copies, leading to multiple DNNs with shared blocks in their former parts and independent blocks in their latter parts. Each of these DNNs is associated with a unique DA and a newly devised loss that allows comprehensively learning from the data generated by all DA methods and the outputs from all DNNs in an online and adaptive way. The overall loss, i.e., the sum of each DNN's loss, is used for training the DNN. Eventually, one of the DNNs with the best validation performance is chosen for inference. We implement the proposed framework by using three distinct DA methods and apply it for training representative DNNs. Experiments on the popular benchmarks of image classification demonstrate the superiority of our method to several existing single-DA and multi-DA based training methods.