 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut-of-distribution generalization of deep-learning surrogates for 2D PDE-generated dynamics in the small-data regime
Jan 13, 2026Partial differential equations (PDEs) are a central tool for modeling the dynamics of physical, engineering, and materials systems, but high-fidelity simulations are often computationally expensive. At the same time, many scientific applications can be viewed as the evolution of spatially distributed fields, making data-driven forecasting of such fields a core task in scientific machine learning. In this work we study autoregressive deep-learning surrogates for two-dimensional PDE dynamics on periodic domains, focusing on generalization to out-of-distribution initial conditions within a fixed PDE and parameter regime and on strict small-data settings with at most $\mathcal{O}(10^2)$ simulated trajectories per system. We introduce a multi-channel U-Net [...], evaluate it on five qualitatively different PDE families and compare it to ViT, AFNO, PDE-Transformer, and KAN-UNet under a common training setup. Across all datasets, me-UNet matches or outperforms these more complex architectures in terms of field-space error, spectral similarity, and physics-based metrics for in-distribution rollouts, while requiring substantially less training time. It also generalizes qualitatively to unseen initial conditions with as few as $\approx 20$ training simulations. A data-efficiency study and Grad-CAM analysis further suggest that, in small-data periodic 2D PDE settings, convolutional architectures with inductive biases aligned to locality and periodic boundary conditions remain strong contenders for accurate and moderately out-of-distribution-robust surrogate modeling.
Combining unsupervised and supervised learning in microscopy enables defect analysis of a full 4H-SiC wafer
Feb 20, 2024



Detecting and analyzing various defect types in semiconductor materials is an important prerequisite for understanding the underlying mechanisms as well as tailoring the production processes. Analysis of microscopy images that reveal defects typically requires image analysis tasks such as segmentation and object detection. With the permanently increasing amount of data that is produced by experiments, handling these tasks manually becomes more and more impossible. In this work, we combine various image analysis and data mining techniques for creating a robust and accurate, automated image analysis pipeline. This allows for extracting the type and position of all defects in a microscopy image of a KOH-etched 4H-SiC wafer that was stitched together from approximately 40,000 individual images.
Efficient Surrogate Models for Materials Science Simulations: Machine Learning-based Prediction of Microstructure Properties
Sep 01, 2023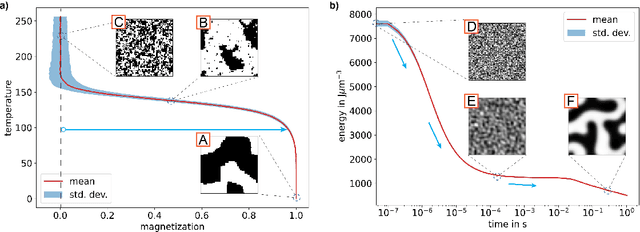
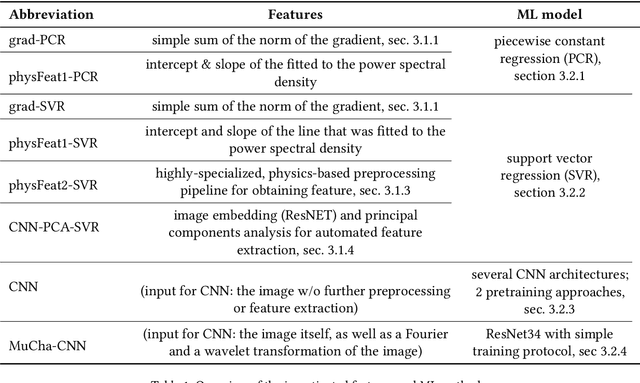
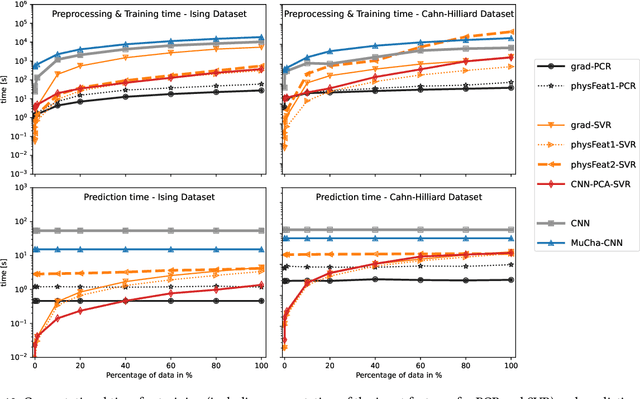
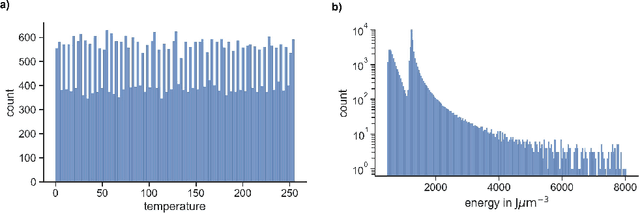
Determining, understanding, and predicting the so-called structure-property relation is an important task in many scientific disciplines, such as chemistry, biology, meteorology, physics, engineering, and materials science. Structure refers to the spatial distribution of, e.g., substances, material, or matter in general, while property is a resulting characteristic that usually depends in a non-trivial way on spatial details of the structure. Traditionally, forward simulations models have been used for such tasks. Recently, several machine learning algorithms have been applied in these scientific fields to enhance and accelerate simulation models or as surrogate models. In this work, we develop and investigate the applications of six machine learning techniques based on two different datasets from the domain of materials science: data from a two-dimensional Ising model for predicting the formation of magnetic domains and data representing the evolution of dual-phase microstructures from the Cahn-Hilliard model. We analyze the accuracy and robustness of all models and elucidate the reasons for the differences in their performances. The impact of including domain knowledge through tailored features is studied, and general recommendations based on the availability and quality of training data are derived from this.