 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Prototype: Divide-and-conquer Proxies for Few-shot Segmentation
Apr 21, 2022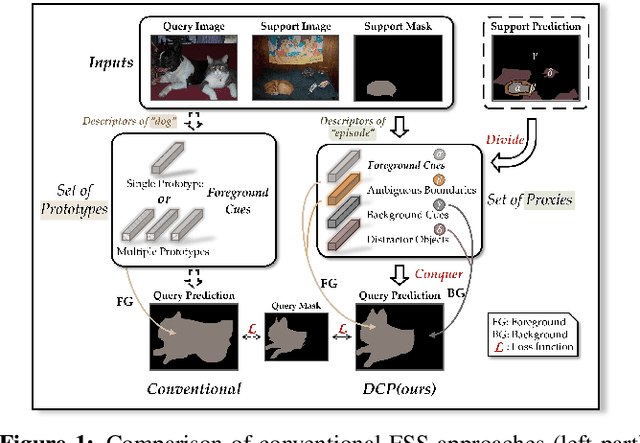

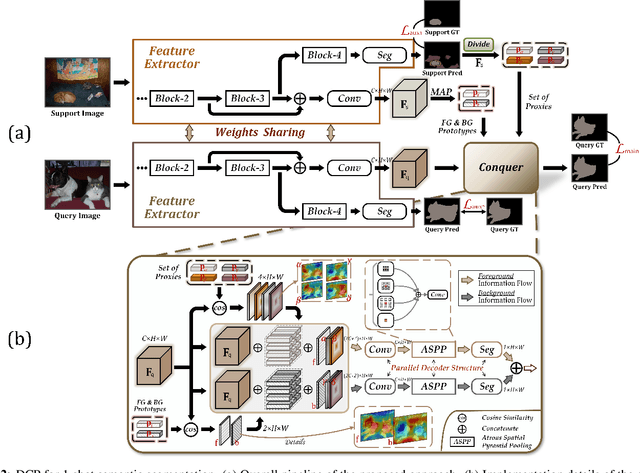

Few-shot segmentation, which aims to segment unseen-class objects given only a handful of densely labeled samples, has received widespread attention from the community. Existing approaches typically follow the prototype learning paradigm to perform meta-inference, which fails to fully exploit the underlying information from support image-mask pairs, resulting in various segmentation failures, e.g., incomplete objects, ambiguous boundaries, and distractor activation. To this end, we propose a simple yet versatile framework in the spirit of divide-and-conquer. Specifically, a novel self-reasoning scheme is first implemented on the annotated support image, and then the coarse segmentation mask is divided into multiple regions with different properties. Leveraging effective masked average pooling operations, a series of support-induced proxies are thus derived, each playing a specific role in conquering the above challenges. Moreover, we devise a unique parallel decoder structure that integrates proxies with similar attributes to boost the discrimination power. Our proposed approach, named divide-and-conquer proxies (DCP), allows for the development of appropriate and reliable information as a guide at the "episode" level, not just about the object cues themselves. Extensive experiments on PASCAL-5i and COCO-20i demonstrate the superiority of DCP over conventional prototype-based approaches (up to 5~10% on average), which also establishes a new state-of-the-art. Code is available at github.com/chunbolang/DCP.
Learning What Not to Segment: A New Perspective on Few-Shot Segmentation
Mar 29, 2022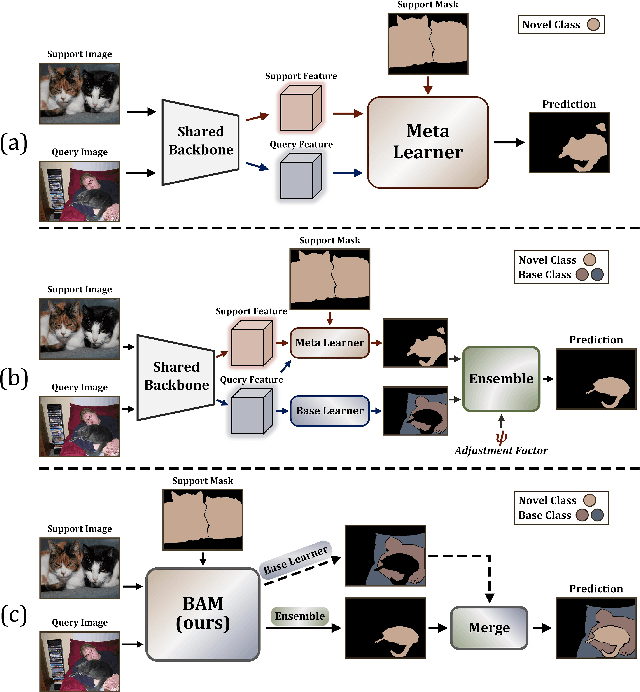
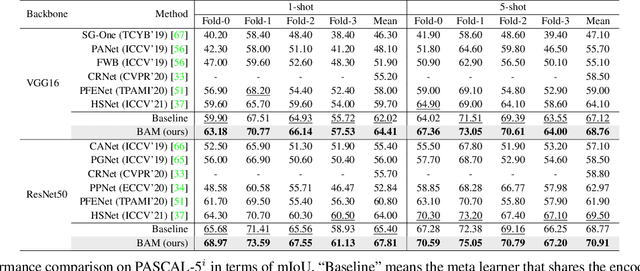
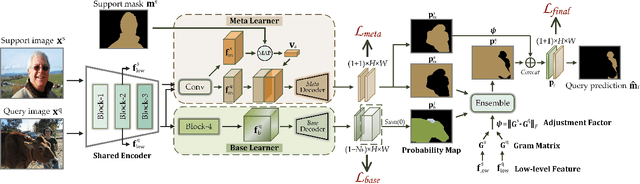
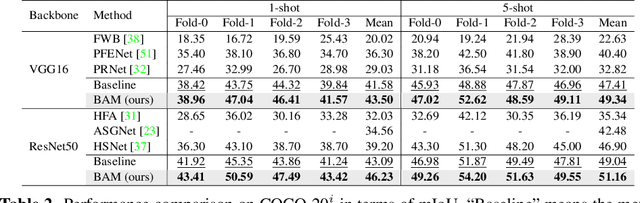
Recently few-shot segmentation (FSS) has been extensively developed. Most previous works strive to achieve generalization through the meta-learning framework derived from classification tasks; however, the trained models are biased towards the seen classes instead of being ideally class-agnostic, thus hindering the recognition of new concepts. This paper proposes a fresh and straightforward insight to alleviate the problem. Specifically, we apply an additional branch (base learner) to the conventional FSS model (meta learner) to explicitly identify the targets of base classes, i.e., the regions that do not need to be segmented. Then, the coarse results output by these two learners in parallel are adaptively integrated to yield precise segmentation prediction. Considering the sensitivity of meta learner, we further introduce an adjustment factor to estimate the scene differences between the input image pairs for facilitating the model ensemble forecasting. The substantial performance gains on PASCAL-5i and COCO-20i verify the effectiveness, and surprisingly, our versatile scheme sets a new state-of-the-art even with two plain learners. Moreover, in light of the unique nature of the proposed approach, we also extend it to a more realistic but challenging setting, i.e., generalized FSS, where the pixels of both base and novel classes are required to be determined. The source code is available at github.com/chunbolang/BAM.