 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInf-CP: A Reliable Channel Pruning based on Channel Influence
Dec 05, 2021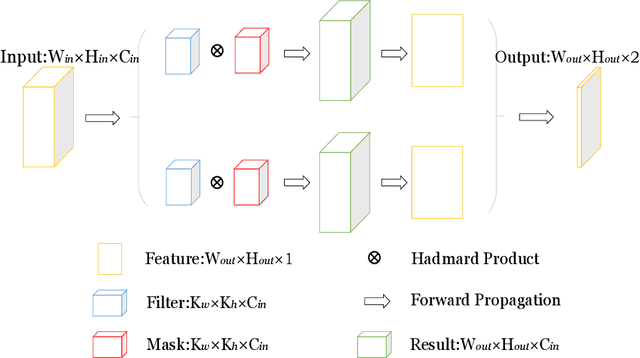
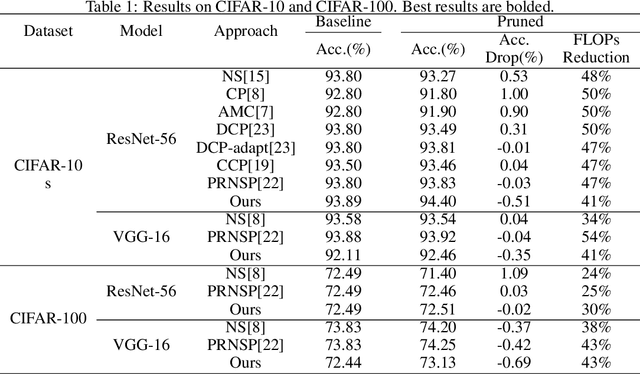

One of the most effective methods of channel pruning is to trim on the basis of the importance of each neuron. However, measuring the importance of each neuron is an NP-hard problem. Previous works have proposed to trim by considering the statistics of a single layer or a plurality of successive layers of neurons. These works cannot eliminate the influence of different data on the model in the reconstruction error, and currently, there is no work to prove that the absolute values of the parameters can be directly used as the basis for judging the importance of the weights. A more reasonable approach is to eliminate the difference between batch data that accurately measures the weight of influence. In this paper, we propose to use ensemble learning to train a model for different batches of data and use the influence function (a classic technique from robust statistics) to learn the algorithm to track the model's prediction and return its training parameter gradient, so that we can determine the responsibility for each parameter, which we call "influence", in the prediction process. In addition, we theoretically prove that the back-propagation of the deep network is a first-order Taylor approximation of the influence function of the weights. We perform extensive experiments to prove that pruning based on the influence function using the idea of ensemble learning will be much more effective than just focusing on error reconstruction. Experiments on CIFAR shows that the influence pruning achieves the state-of-the-art result.