 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaltNav: Reactive Visual Halting over Lightweight Topological Priors for Robust Vision-Language Navigation
Mar 13, 2026Vision-and-Language Navigation (VLN) is shifting from rigid, step-by-step instruction following toward open-vocabulary, goal-oriented autonomy. Achieving this transition without exhaustive routing prompts requires agents to leverage structural priors. While prior work often assumes computationally heavy 2D/3D metric maps, we instead exploit a lightweight, text-based osmAG (OpenStreetMap Area Graph), a floorplan-level topological representation that is easy to obtain and maintain. However, global planning over a prior map alone is brittle in real-world deployments, where local connectivity can change (e.g., closed doors or crowded passages), leading to execution-time failures. To address this gap, we propose a hierarchical navigation framework HaltNav that couples the robust global planning of osmAG with the local exploration and instruction-grounding capability of VLN. Our approach features an MLLM-based brain module, which is capable of high-level task grounding and obstruction awareness. Conditioned on osmAG, the brain converts the global route into a sequence of localized execution snippets, providing the VLN executor with prior-grounded, goal-centric sub-instructions. Meanwhile, it detects local anomalies via a mechanism we term Reactive Visual Halting (RVH), which interrupts the local control loop, updates osmAG by invalidating the corresponding topology, and triggers replanning to orchestrate a viable detour. To train this halting capability efficiently, we introduce a data synthesis pipeline that leverages generative models to inject realistic obstacles into otherwise navigable scenes, substantially enriching hard negative samples. Extensive experiments demonstrate that our hierarchical framework outperforms several baseline methods without tedious language instructions, and significantly improves robustness for long-horizon vision-language navigation under environmental changes.
Multi-FEAT: Multi-Feature Edge AlignmenT for Targetless Camera-LiDAR Calibration
Jul 14, 2022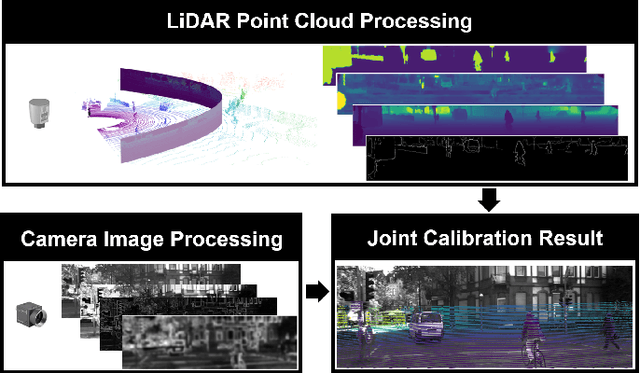
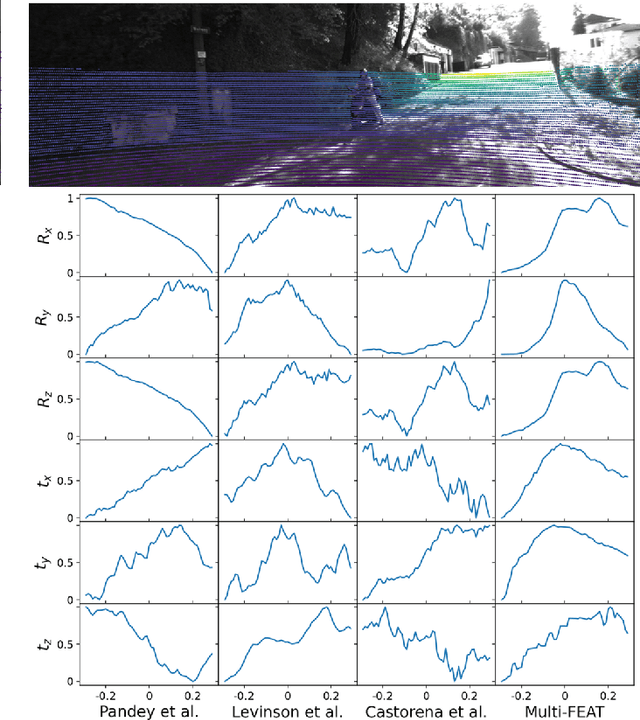
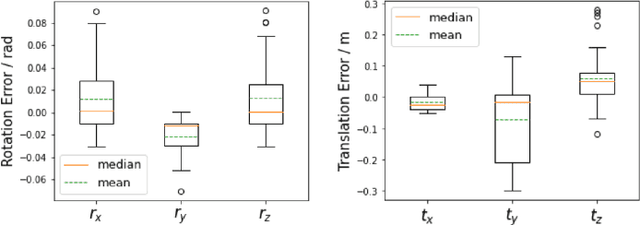
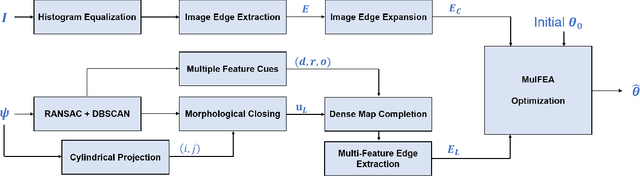
The accurate environment perception of automobiles and UAVs (Unmanned Ariel Vehicles) relies on the precision of onboard sensors, which require reliable in-field calibration. This paper introduces a novel approach for targetless camera-LiDAR extrinsic calibration called Multi-FEAT (Multi-Feature Edge AlignmenT). Multi-FEAT uses the cylindrical projection model to transform the 2D(Camera)-3D(LiDAR) calibration problem into a 2D-2D calibration problem, and exploits various LiDAR feature information to supplement the sparse LiDAR point cloud boundaries. In addition, a feature matching function with a precision factor is designed to improve the smoothness of the solution space. The performance of the proposed Multi-FEAT algorithm is evaluated using the KITTI dataset, and our approach shows more reliable results, as compared with several existing targetless calibration methods. We summarize our results and present potential directions for future work.