 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShort-Term Aggregated Residential Load Forecasting using BiLSTM and CNN-BiLSTM
Feb 10, 2023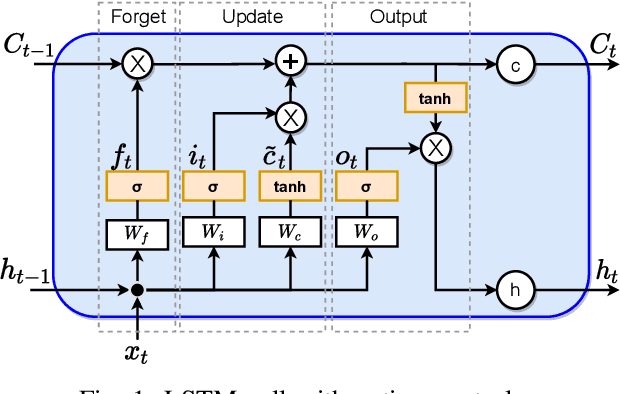
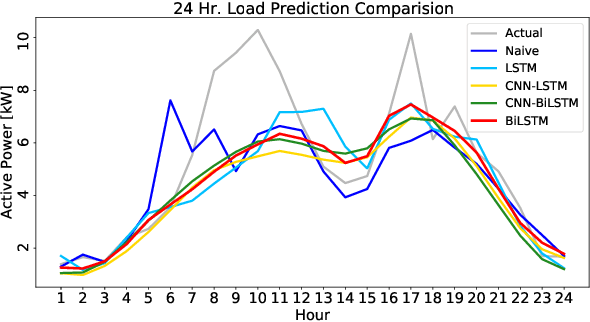

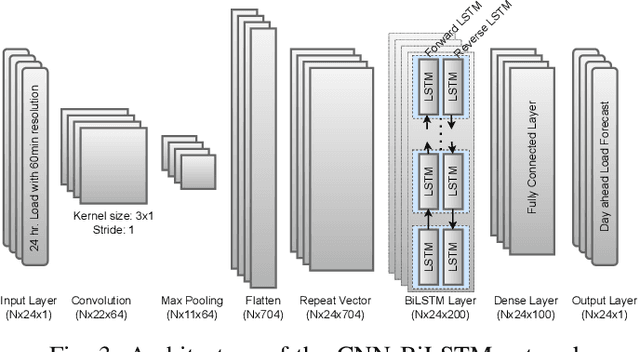
Higher penetration of renewable and smart home technologies at the residential level challenges grid stability as utility-customer interactions add complexity to power system operations. In response, short-term residential load forecasting has become an increasing area of focus. However, forecasting at the residential level is challenging due to the higher uncertainties involved. Recently deep neural networks have been leveraged to address this issue. This paper investigates the capabilities of a bidirectional long short-term memory (BiLSTM) and a convolutional neural network-based BiLSTM (CNN-BiLSTM) to provide a day ahead (24 hr.) forecasting at an hourly resolution while minimizing the root mean squared error (RMSE) between the actual and predicted load demand. Using a publicly available dataset consisting of 38 homes, the BiLSTM and CNN-BiLSTM models are trained to forecast the aggregated active power demand for each hour within a 24 hr. span, given the previous 24 hr. load data. The BiLSTM model achieved the lowest RMSE of 1.4842 for the overall daily forecast. In addition, standard LSTM and CNN-LSTM models are trained and compared with the BiLSTM architecture. The RMSE of BiLSTM is 5.60%, 2.85% and 2.60% lower than the LSTM, CNN-LSTM and CNN-BiLSTM models respectively. The source code of this work is available at https://github.com/Varat7v2/STLF-BiLSTM-CNNBiLSTM.git.
* This article has been accepted for publication in 2022 International Conference on Innovation and Intelligence for Informatics, Computing, and Technologies (3ICT). This preprint is for personal use - that is solely for the purpose of research, but republication/redistribution requires IEEE permission. Please check IEEE website for more information
Adaptive Threshold for Better Performance of the Recognition and Re-identification Models
Dec 28, 2020
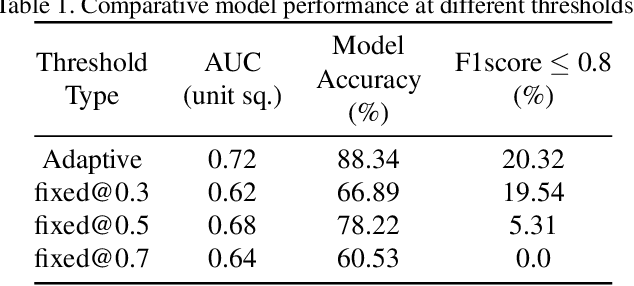


Choosing a decision threshold is one of the challenging job in any classification tasks. How much the model is accurate, if the deciding boundary is not picked up carefully, its entire performance would go in vain. On the other hand, for imbalance classification where one of the classes is dominant over another, relying on the conventional method of choosing threshold would result in poor performance. Even if the threshold or decision boundary is properly chosen based on machine learning strategies like SVM and decision tree, it will fail at some point for dynamically varying databases and in case of identity-features that are more or less similar, like in face recognition and person re-identification models. Hence, with the need for adaptability of the decision threshold selection for imbalanced classification and incremental database size, an online optimization-based statistical feature learning adaptive technique is developed and tested on the LFW datasets and self-prepared athletes datasets. This method of adopting adaptive threshold resulted in 12-45% improvement in the model accuracy compared to the fixed threshold {0.3,0.5,0.7} that are usually taken via the hit-and-trial method in any classification and identification tasks. Source code for the complete algorithm is available at: https://github.com/Varat7v2/adaptive-threshold