Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Bounds for Moment-Based Domain Adaptation
Feb 19, 2020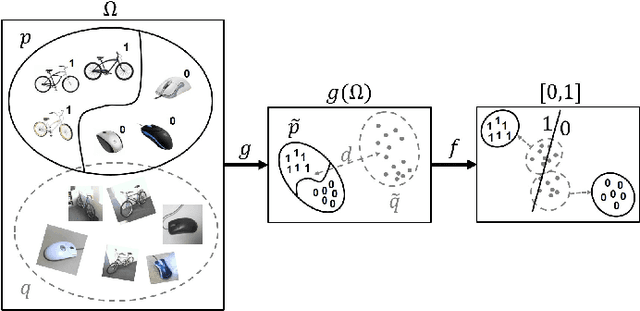
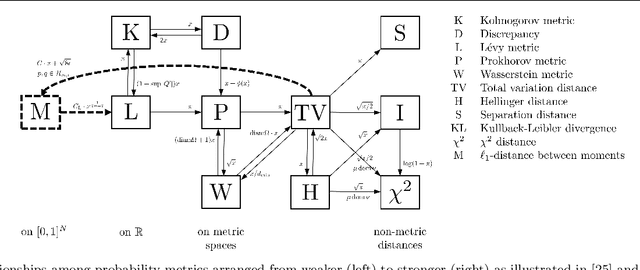
Domain adaptation algorithms are designed to minimize the misclassification risk of a discriminative model for a target domain with little training data by adapting a model from a source domain with a large amount of training data. Standard approaches measure the adaptation discrepancy based on distance measures between the empirical probability distributions in the source and target domain. In this setting, we address the problem of deriving learning bounds under practice-oriented general conditions on the underlying probability distributions. As a result, we obtain learning bounds for domain adaptation based on finitely many moments and smoothness conditions.
Via