 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePassed the Turing Test: Living in Turing Futures
Sep 11, 2024The world has seen the emergence of machines based on pretrained models, transformers, also known as generative artificial intelligences for their ability to produce various types of content, including text, images, audio, and synthetic data. Without resorting to preprogramming or special tricks, their intelligence grows as they learn from experience, and to ordinary people, they can appear human-like in conversation. This means that they can pass the Turing test, and that we are now living in one of many possible Turing futures where machines can pass for what they are not. However, the learning machines that Turing imagined would pass his imitation tests were machines inspired by the natural development of the low-energy human cortex. They would be raised like human children and naturally learn the ability to deceive an observer. These ``child machines,'' Turing hoped, would be powerful enough to have an impact on society and nature.
Turing's Test, a Beautiful Thought Experiment
Dec 18, 2023In the wake of large language models, there has been a resurgence of claims and questions about the Turing test and its value for AI, which are reminiscent of decades of practical "Turing" tests. If AI were quantum physics, by now several "Schr\"odinger's" cats could have been killed. Better late than never, it is time for a historical reconstruction of Turing's beautiful thought experiment. In this paper I present a wealth of evidence, including new archival sources, give original answers to several open questions about Turing's 1950 paper, and address the core question of the value of Turing's test.
Mediation Challenges and Socio-Technical Gaps for Explainable Deep Learning Applications
Jul 16, 2019


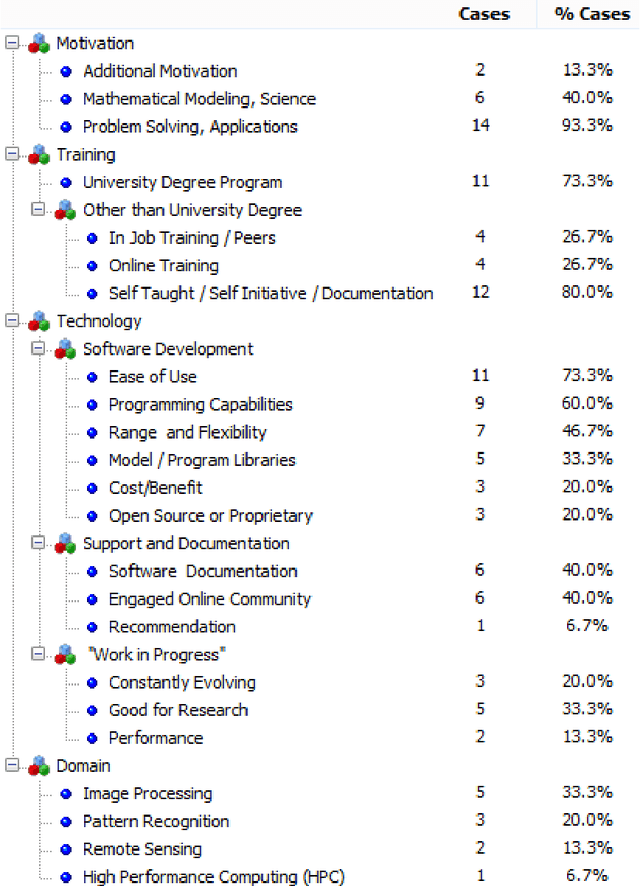
The presumed data owners' right to explanations brought about by the General Data Protection Regulation in Europe has shed light on the social challenges of explainable artificial intelligence (XAI). In this paper, we present a case study with Deep Learning (DL) experts from a research and development laboratory focused on the delivery of industrial-strength AI technologies. Our aim was to investigate the social meaning (i.e. meaning to others) that DL experts assign to what they do, given a richly contextualized and familiar domain of application. Using qualitative research techniques to collect and analyze empirical data, our study has shown that participating DL experts did not spontaneously engage into considerations about the social meaning of machine learning models that they build. Moreover, when explicitly stimulated to do so, these experts expressed expectations that, with real-world DL application, there will be available mediators to bridge the gap between technical meanings that drive DL work, and social meanings that AI technology users assign to it. We concluded that current research incentives and values guiding the participants' scientific interests and conduct are at odds with those required to face some of the scientific challenges involved in advancing XAI, and thus responding to the alleged data owners' right to explanations or similar societal demands emerging from current debates. As a concrete contribution to mitigate what seems to be a more general problem, we propose three preliminary XAI Mediation Challenges with the potential to bring together technical and social meanings of DL applications, as well as to foster much needed interdisciplinary collaboration among AI and the Social Sciences researchers.
Modeling Epistemological Principles for Bias Mitigation in AI Systems: An Illustration in Hiring Decisions
Nov 20, 2017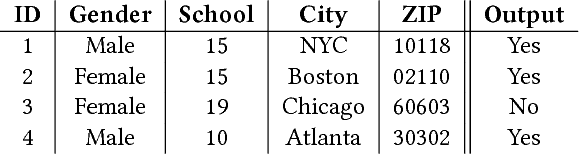
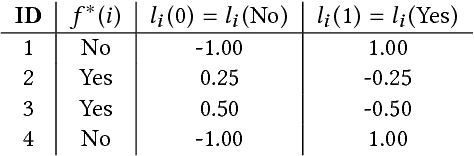
Artificial Intelligence (AI) has been used extensively in automatic decision making in a broad variety of scenarios, ranging from credit ratings for loans to recommendations of movies. Traditional design guidelines for AI models focus essentially on accuracy maximization, but recent work has shown that economically irrational and socially unacceptable scenarios of discrimination and unfairness are likely to arise unless these issues are explicitly addressed. This undesirable behavior has several possible sources, such as biased datasets used for training that may not be detected in black-box models. After pointing out connections between such bias of AI and the problem of induction, we focus on Popper's contributions after Hume's, which offer a logical theory of preferences. An AI model can be preferred over others on purely rational grounds after one or more attempts at refutation based on accuracy and fairness. Inspired by such epistemological principles, this paper proposes a structured approach to mitigate discrimination and unfairness caused by bias in AI systems. In the proposed computational framework, models are selected and enhanced after attempts at refutation. To illustrate our discussion, we focus on hiring decision scenarios where an AI system filters in which job applicants should go to the interview phase.
Show me the material evidence: Initial experiments on evaluating hypotheses from user-generated multimedia data
Nov 11, 2016



Subjective questions such as `does neymar dive', or `is clinton lying', or `is trump a fascist', are popular queries to web search engines, as can be seen by autocompletion suggestions on Google, Yahoo and Bing. In the era of cognitive computing, beyond search, they could be handled as hypotheses issued for evaluation. Our vision is to leverage on unstructured data and metadata of the rich user-generated multimedia that is often shared as material evidence in favor or against hypotheses in social media platforms. In this paper we present two preliminary experiments along those lines and discuss challenges for a cognitive computing system that collects material evidence from user-generated multimedia towards aggregating it into some form of collective decision on the hypothesis.
A note on the complexity of the causal ordering problem
Jun 13, 2016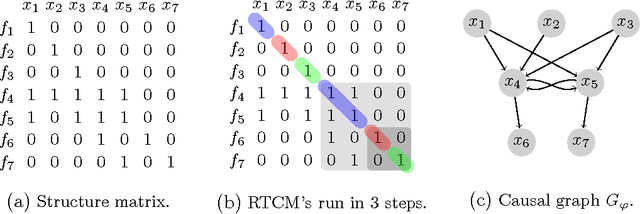

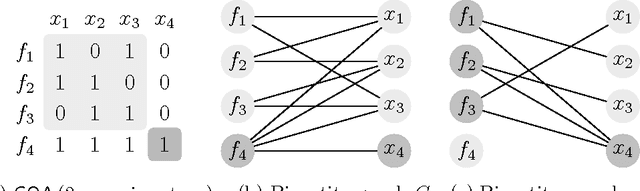
In this note we provide a concise report on the complexity of the causal ordering problem, originally introduced by Simon to reason about causal dependencies implicit in systems of mathematical equations. We show that Simon's classical algorithm to infer causal ordering is NP-Hard---an intractability previously guessed but never proven. We present then a detailed account based on Nayak's suggested algorithmic solution (the best available), which is dominated by computing transitive closure---bounded in time by $O(|\mathcal V|\cdot |\mathcal S|)$, where $\mathcal S(\mathcal E, \mathcal V)$ is the input system structure composed of a set $\mathcal E$ of equations over a set $\mathcal V$ of variables with number of variable appearances (density) $|\mathcal S|$. We also comment on the potential of causal ordering for emerging applications in large-scale hypothesis management and analytics.
* 25 pages, 4 figures
Managing large-scale scientific hypotheses as uncertain and probabilistic data
Feb 12, 2015



In view of the paradigm shift that makes science ever more data-driven, in this thesis we propose a synthesis method for encoding and managing large-scale deterministic scientific hypotheses as uncertain and probabilistic data. In the form of mathematical equations, hypotheses symmetrically relate aspects of the studied phenomena. For computing predictions, however, deterministic hypotheses can be abstracted as functions. We build upon Simon's notion of structural equations in order to efficiently extract the (so-called) causal ordering between variables, implicit in a hypothesis structure (set of mathematical equations). We show how to process the hypothesis predictive structure effectively through original algorithms for encoding it into a set of functional dependencies (fd's) and then performing causal reasoning in terms of acyclic pseudo-transitive reasoning over fd's. Such reasoning reveals important causal dependencies implicit in the hypothesis predictive data and guide our synthesis of a probabilistic database. Like in the field of graphical models in AI, such a probabilistic database should be normalized so that the uncertainty arisen from competing hypotheses is decomposed into factors and propagated properly onto predictive data by recovering its joint probability distribution through a lossless join. That is motivated as a design-theoretic principle for data-driven hypothesis management and predictive analytics. The method is applicable to both quantitative and qualitative deterministic hypotheses and demonstrated in realistic use cases from computational science.