 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying Distillation with Personalization in Federated Learning
May 31, 2021

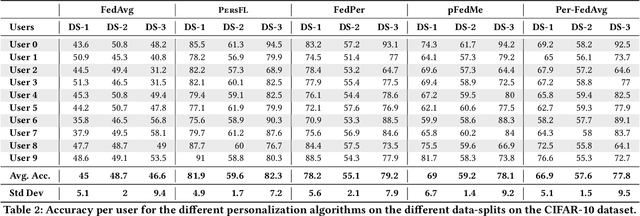
Federated learning (FL) is a decentralized privacy-preserving learning technique in which clients learn a joint collaborative model through a central aggregator without sharing their data. In this setting, all clients learn a single common predictor (FedAvg), which does not generalize well on each client's local data due to the statistical data heterogeneity among clients. In this paper, we address this problem with PersFL, a discrete two-stage personalized learning algorithm. In the first stage, PersFL finds the optimal teacher model of each client during the FL training phase. In the second stage, PersFL distills the useful knowledge from optimal teachers into each user's local model. The teacher model provides each client with some rich, high-level representation that a client can easily adapt to its local model, which overcomes the statistical heterogeneity present at different clients. We evaluate PersFL on CIFAR-10 and MNIST datasets using three data-splitting strategies to control the diversity between clients' data distributions. We empirically show that PersFL outperforms FedAvg and three state-of-the-art personalization methods, pFedMe, Per-FedAvg, and FedPer on majority data-splits with minimal communication cost. Further, we study the performance of PersFL on different distillation objectives, how this performance is affected by the equitable notion of fairness among clients, and the number of required communication rounds. PersFL code is available at https://tinyurl.com/hdh5zhxs for public use and validation.