 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFathomVerse: A community science dataset for ocean animal discovery
Dec 02, 2024



Can computer vision help us explore the ocean? The ultimate challenge for computer vision is to recognize any visual phenomena, more than only the objects and animals humans encounter in their terrestrial lives. Previous datasets have explored everyday objects and fine-grained categories humans see frequently. We present the FathomVerse v0 detection dataset to push the limits of our field by exploring animals that rarely come in contact with people in the deep sea. These animals present a novel vision challenge. The FathomVerse v0 dataset consists of 3843 images with 8092 bounding boxes from 12 distinct morphological groups recorded at two locations on the deep seafloor that are new to computer vision. It features visually perplexing scenarios such as an octopus intertwined with a sea star, and confounding categories like vampire squids and sea spiders. This dataset can push forward research on topics like fine-grained transfer learning, novel category discovery, species distribution modeling, and carbon cycle analysis, all of which are important to the care and husbandry of our planet.
The FathomNet2023 Competition Dataset
Jul 17, 2023
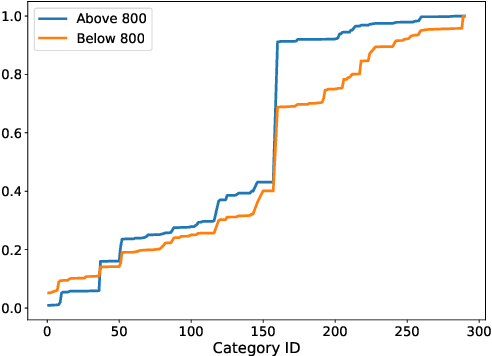

Ocean scientists have been collecting visual data to study marine organisms for decades. These images and videos are extremely valuable both for basic science and environmental monitoring tasks. There are tools for automatically processing these data, but none that are capable of handling the extreme variability in sample populations, image quality, and habitat characteristics that are common in visual sampling of the ocean. Such distribution shifts can occur over very short physical distances and in narrow time windows. Creating models that are able to recognize when an image or video sequence contains a new organism, an unusual collection of animals, or is otherwise out-of-sample is critical to fully leverage visual data in the ocean. The FathomNet2023 competition dataset presents a realistic scenario where the set of animals in the target data differs from the training data. The challenge is both to identify the organisms in a target image and assess whether it is out-of-sample.
FathomNet: A global underwater image training set for enabling artificial intelligence in the ocean
Oct 02, 2021
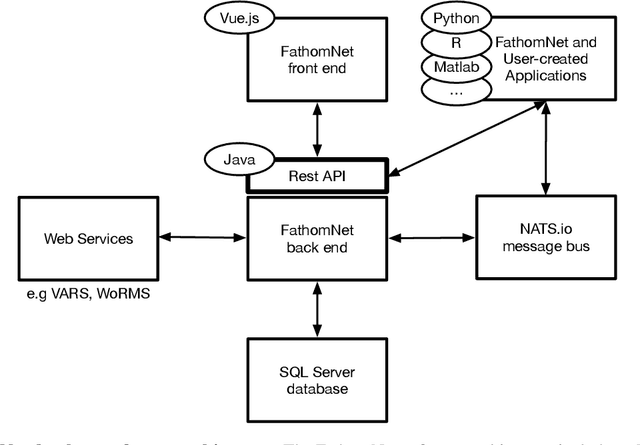
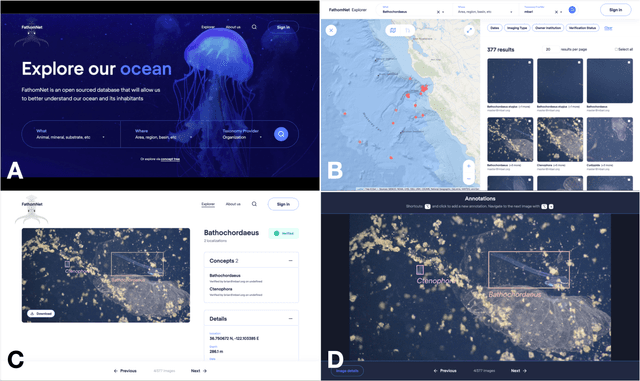
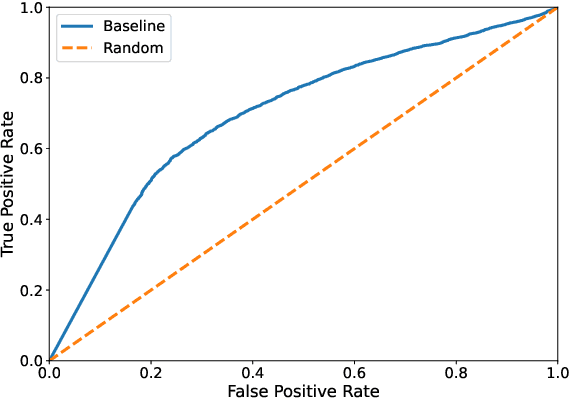
Ocean-going platforms are integrating high-resolution camera feeds for observation and navigation, producing a deluge of visual data. The volume and rate of this data collection can rapidly outpace researchers' abilities to process and analyze them. Recent advances in machine learning enable fast, sophisticated analysis of visual data, but have had limited success in the ocean due to lack of data set standardization, insufficient formatting, and aggregation of existing, expertly curated imagery for use by data scientists. To address this need, we have built FathomNet, a public platform that makes use of existing, expertly curated data. Initial efforts have leveraged MBARI's Video Annotation and Reference System and annotated deep sea video database, which has more than 7M annotations, 1M frame grabs, and 5k terms in the knowledgebase, with additional contributions by National Geographic Society (NGS) and NOAA's Office of Ocean Exploration and Research. FathomNet has over 160k localizations of 1.4k midwater and benthic classes, and contains more than 70k iconic and non-iconic views of marine animals, underwater equipment, debris, etc. We demonstrate how machine learning models trained on FathomNet data can be applied across different institutional video data, and enable automated acquisition and tracking of midwater animals using a remotely operated vehicle. As FathomNet continues to develop and incorporate more image data from other oceanographic community members, this effort will enable scientists, explorers, policymakers, storytellers, and the public to understand and care for our ocean.
Propagating Uncertainty in Multi-Stage Bayesian Convolutional Neural Networks with Application to Pulmonary Nodule Detection
Dec 01, 2017

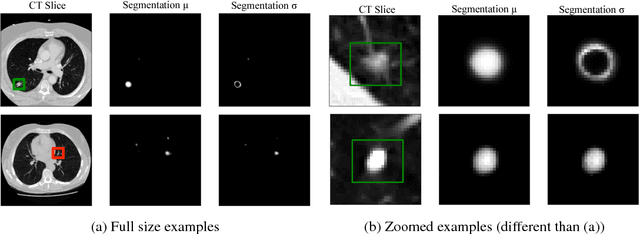
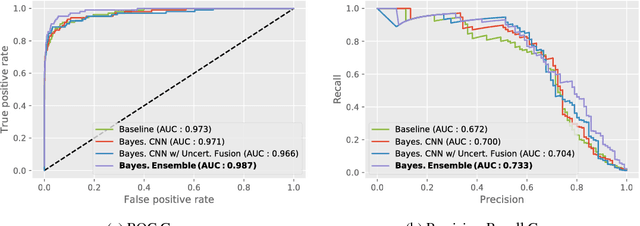
Motivated by the problem of computer-aided detection (CAD) of pulmonary nodules, we introduce methods to propagate and fuse uncertainty information in a multi-stage Bayesian convolutional neural network (CNN) architecture. The question we seek to answer is "can we take advantage of the model uncertainty provided by one deep learning model to improve the performance of the subsequent deep learning models and ultimately of the overall performance in a multi-stage Bayesian deep learning architecture?". Our experiments show that propagating uncertainty through the pipeline enables us to improve the overall performance in terms of both final prediction accuracy and model confidence.