 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Parallel Adaptive Clustering and its Application to Streaming Data
Apr 06, 2021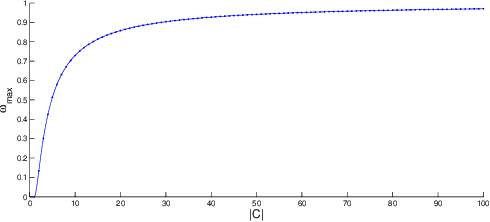

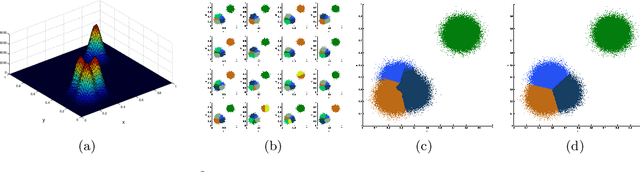

This paper presents a parallel adaptive clustering (PAC) algorithm to automatically classify data while simultaneously choosing a suitable number of classes. Clustering is an important tool for data analysis and understanding in a broad set of areas including data reduction, pattern analysis, and classification. However, the requirement to specify the number of clusters in advance and the computational burden associated with clustering large sets of data persist as challenges in clustering. We propose a new parallel adaptive clustering (PAC) algorithm that addresses these challenges by adaptively computing the number of clusters and leveraging the power of parallel computing. The algorithm clusters disjoint subsets of the data on parallel computation threads. We develop regularized set \mi{k}-means to efficiently cluster the results from the parallel threads. A refinement step further improves the clusters. The PAC algorithm offers the capability to adaptively cluster data sets which change over time by reusing the information from previous time steps to decrease computation. We provide theoretical analysis and numerical experiments to characterize the performance of the method, validate its properties, and demonstrate the computational efficiency of the method.