 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-dimensional regression with potential prior information on variable importance
Sep 23, 2021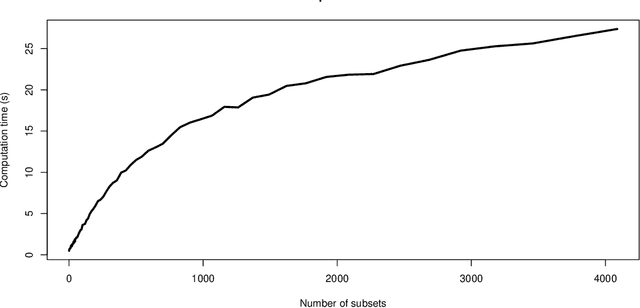



There are a variety of settings where vague prior information may be available on the importance of predictors in high-dimensional regression settings. Examples include ordering on the variables offered by their empirical variances (which is typically discarded through standardisation), the lag of predictors when fitting autoregressive models in time series settings, or the level of missingness of the variables. Whilst such orderings may not match the true importance of variables, we argue that there is little to be lost, and potentially much to be gained, by using them. We propose a simple scheme involving fitting a sequence of models indicated by the ordering. We show that the computational cost for fitting all models when ridge regression is used is no more than for a single fit of ridge regression, and describe a strategy for Lasso regression that makes use of previous fits to greatly speed up fitting the entire sequence of models. We propose to select a final estimator by cross-validation and provide a general result on the quality of the best performing estimator on a test set selected from among a number $M$ of competing estimators in a high-dimensional linear regression setting. Our result requires no sparsity assumptions and shows that only a $\log M$ price is incurred compared to the unknown best estimator. We demonstrate the effectiveness of our approach when applied to missing or corrupted data, and time series settings. An R package is available on github.
Modelling High-Dimensional Categorical Data Using Nonconvex Fusion Penalties
Feb 28, 2020
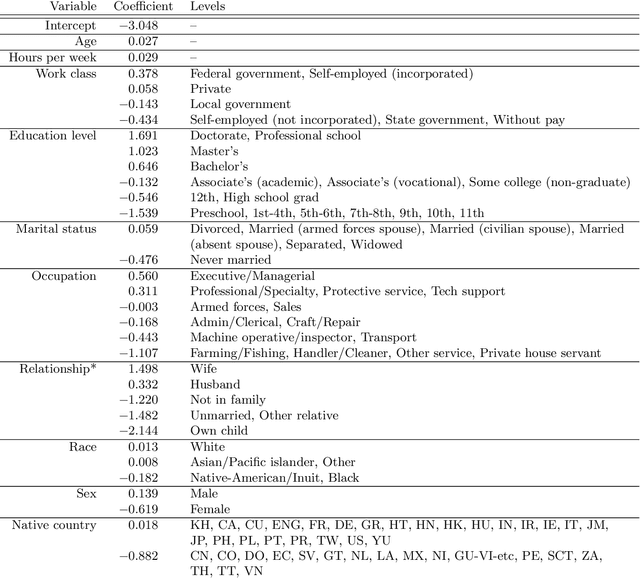
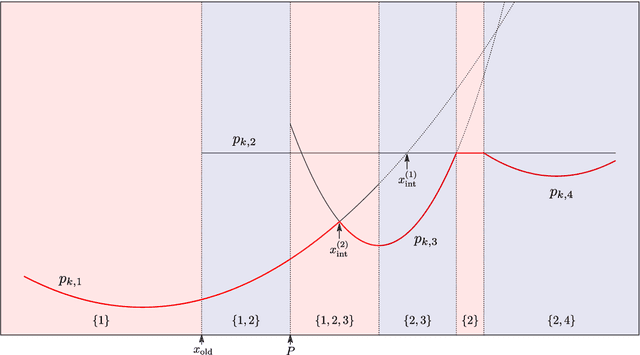

We propose a method for estimation in high-dimensional linear models with nominal categorical data. Our estimator, called SCOPE, fuses levels together by making their corresponding coefficients exactly equal. This is achieved using the minimax concave penalty on differences between the order statistics of the coefficients for a categorical variable, thereby clustering the coefficients. We provide an algorithm for exact and efficient computation of the global minimum of the resulting nonconvex objective in the case with a single variable with potentially many levels, and use this within a block coordinate descent procedure in the multivariate case. We show that an oracle least squares solution that exploits the unknown level fusions is a limit point of the coordinate descent with high probability, provided the true levels have a certain minimum separation; these conditions are known to be minimal in the univariate case. We demonstrate the favourable performance of SCOPE across a range of real and simulated datasets. An R package CatReg implementing SCOPE for linear models and also a version for logistic regression is available on CRAN.