 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic and Systematic Survey of Deep Learning Approaches for Driving Behavior Analysis
Sep 18, 2021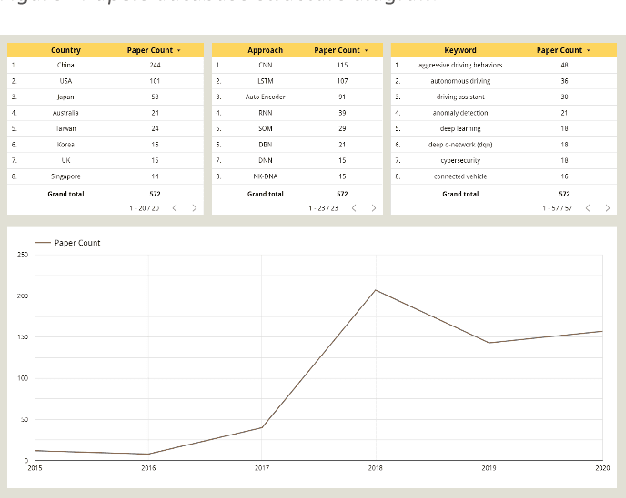
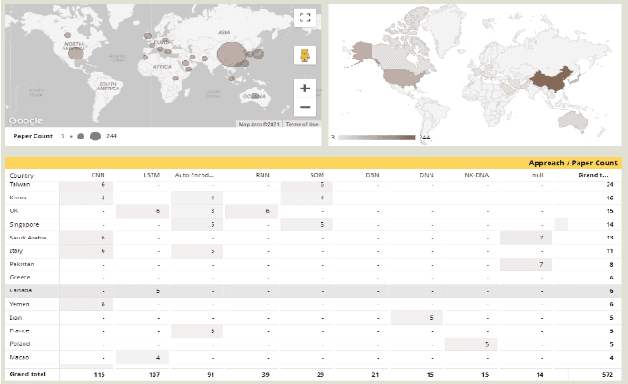

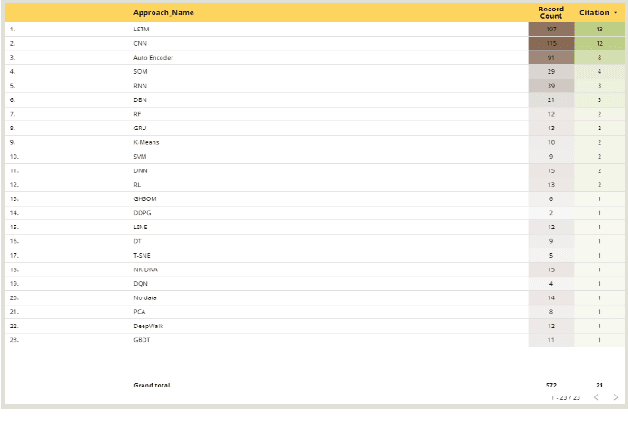
Improper driving results in fatalities, damages, increased energy consumptions, and depreciation of the vehicles. Analyzing driving behaviour could lead to optimize and avoid mentioned issues. By identifying the type of driving and mapping them to the consequences of that type of driving, we can get a model to prevent them. In this regard, we try to create a dynamic survey paper to review and present driving behaviour survey data for future researchers in our research. By analyzing 58 articles, we attempt to classify standard methods and provide a framework for future articles to be examined and studied in different dashboards and updated about trends.
Detection of Alzheimer's Disease Using Graph-Regularized Convolutional Neural Network Based on Structural Similarity Learning of Brain Magnetic Resonance Images
Feb 25, 2021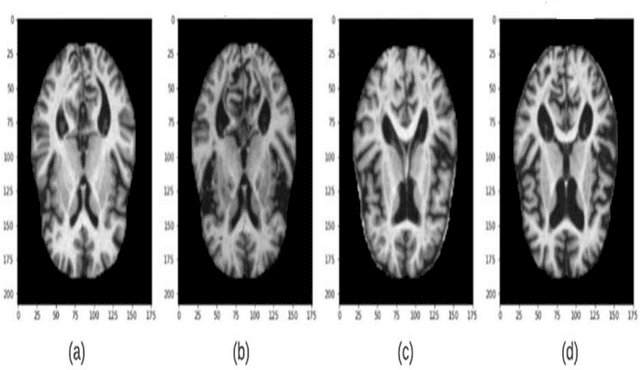

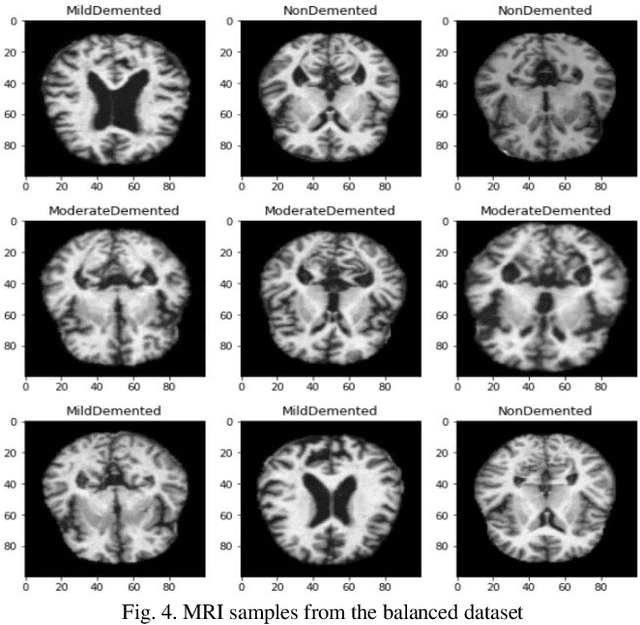

Objective: This paper presents an Alzheimer's disease (AD) detection method based on learning structural similarity between Magnetic Resonance Images (MRIs) and representing this similarity as a graph. Methods: We construct the similarity graph using embedded features of the input image (i.e., Non-Demented (ND), Very Mild Demented (VMD), Mild Demented (MD), and Moderated Demented (MDTD)). We experiment and compare different dimension-reduction and clustering algorithms to construct the best similarity graph to capture the similarity between the same class images using the cosine distance as a similarity measure. We utilize the similarity graph to present (sample) the training data to a convolutional neural network (CNN). We use the similarity graph as a regularizer in the loss function of a CNN model to minimize the distance between the input images and their k-nearest neighbours in the similarity graph while minimizing the categorical cross-entropy loss between the training image predictions and the actual image class labels. Results: We conduct extensive experiments with several pre-trained CNN models and compare the results to other recent methods. Conclusion: Our method achieves superior performance on the testing dataset (accuracy = 0.986, area under receiver operating characteristics curve = 0.998, F1 measure = 0.987). Significance: The classification results show an improvement in the prediction accuracy compared to the other methods. We release all the code used in our experiments to encourage reproducible research in this area