 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Approximation Capabilities of ReLU Activation and Softmax Output Layer in Neural Networks
Feb 10, 2020
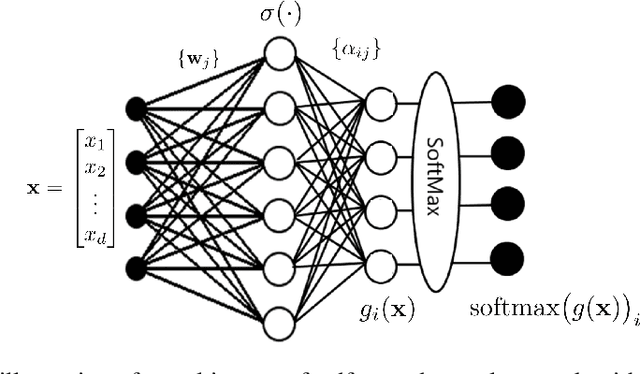

In this paper, we have extended the well-established universal approximator theory to neural networks that use the unbounded ReLU activation function and a nonlinear softmax output layer. We have proved that a sufficiently large neural network using the ReLU activation function can approximate any function in $L^1$ up to any arbitrary precision. Moreover, our theoretical results have shown that a large enough neural network using a nonlinear softmax output layer can also approximate any indicator function in $L^1$, which is equivalent to mutually-exclusive class labels in any realistic multiple-class pattern classification problems. To the best of our knowledge, this work is the first theoretical justification for using the softmax output layers in neural networks for pattern classification.