 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Semantic Rules Detection (ASRD) for Emergent Communication Interpretation
Jan 06, 2026The field of emergent communication within multi-agent systems examines how autonomous agents can independently develop communication strategies, without explicit programming, and adapt them to varied environments. However, few studies have focused on the interpretability of emergent languages. The research exposed in this paper proposes an Automated Semantic Rules Detection (ASRD) algorithm, which extracts relevant patterns in messages exchanged by agents trained with two different datasets on the Lewis Game, which is often studied in the context of emergent communication. ASRD helps at the interpretation of the emergent communication by relating the extracted patterns to specific attributes of the input data, thereby considerably simplifying subsequent analysis.
Improved Soccer Action Spotting using both Audio and Video Streams
Nov 09, 2020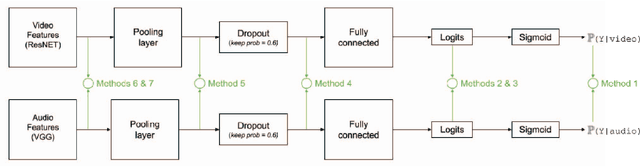
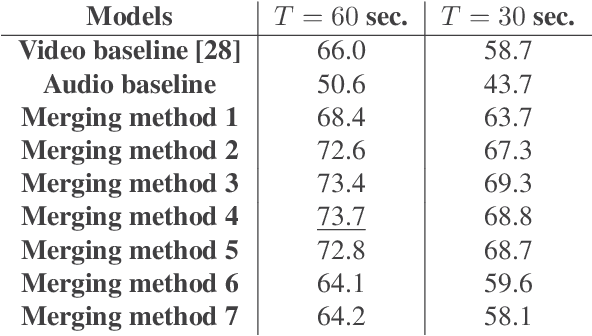
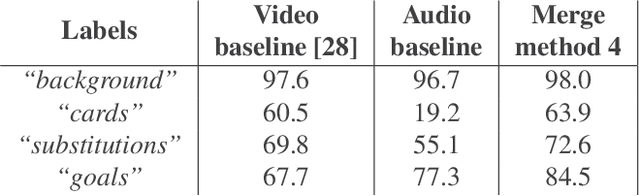
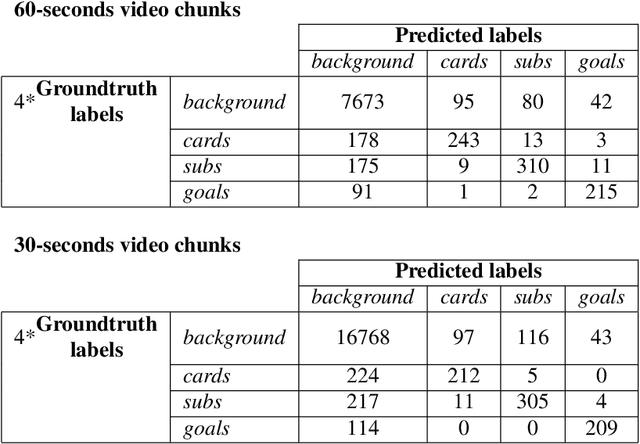
In this paper, we propose a study on multi-modal (audio and video) action spotting and classification in soccer videos. Action spotting and classification are the tasks that consist in finding the temporal anchors of events in a video and determine which event they are. This is an important application of general activity understanding. Here, we propose an experimental study on combining audio and video information at different stages of deep neural network architectures. We used the SoccerNet benchmark dataset, which contains annotated events for 500 soccer game videos from the Big Five European leagues. Through this work, we evaluated several ways to integrate audio stream into video-only-based architectures. We observed an average absolute improvement of the mean Average Precision (mAP) metric of $7.43\%$ for the action classification task and of $4.19\%$ for the action spotting task.
Can adversarial training learn image captioning ?
Oct 31, 2019

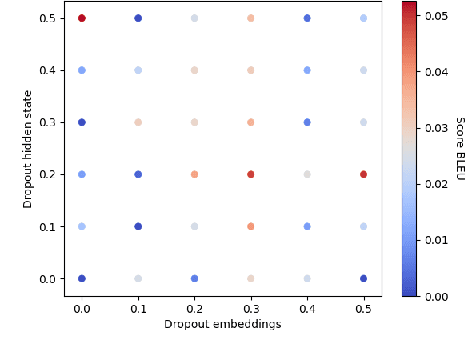
Recently, generative adversarial networks (GAN) have gathered a lot of interest. Their efficiency in generating unseen samples of high quality, especially images, has improved over the years. In the field of Natural Language Generation (NLG), the use of the adversarial setting to generate meaningful sentences has shown to be difficult for two reasons: the lack of existing architectures to produce realistic sentences and the lack of evaluation tools. In this paper, we propose an adversarial architecture related to the conditional GAN (cGAN) that generates sentences according to a given image (also called image captioning). This attempt is the first that uses no pre-training or reinforcement methods. We also explain why our experiment settings can be safely evaluated and interpreted for further works.