 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePostprocessing of point predictions for probabilistic forecasting of electricity prices: Diversity matters
Apr 02, 2024



Operational decisions relying on predictive distributions of electricity prices can result in significantly higher profits compared to those based solely on point forecasts. However, the majority of models developed in both academic and industrial settings provide only point predictions. To address this, we examine three postprocessing methods for converting point forecasts into probabilistic ones: Quantile Regression Averaging, Conformal Prediction, and the recently introduced Isotonic Distributional Regression. We find that while IDR demonstrates the most varied performance, combining its predictive distributions with those of the other two methods results in an improvement of ca. 7.5% compared to a benchmark model with normally distributed errors, over a 4.5-year test period in the German power market spanning the COVID pandemic and the war in Ukraine. Remarkably, the performance of this combination is at par with state-of-the-art Distributional Deep Neural Networks.
Forecasting Electricity Prices
Apr 25, 2022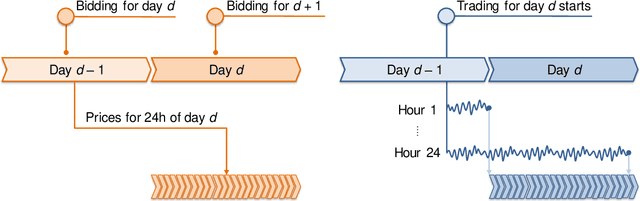
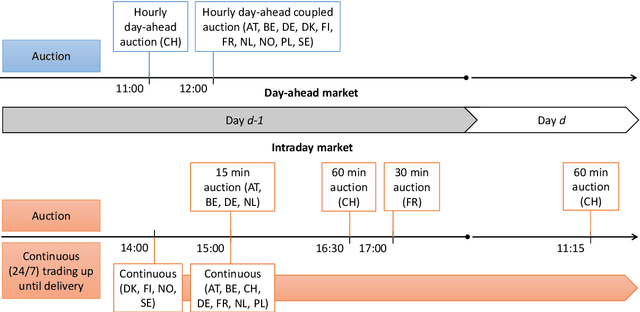
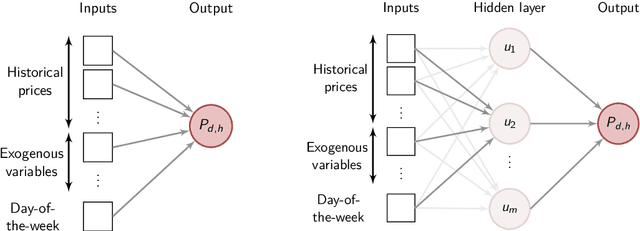
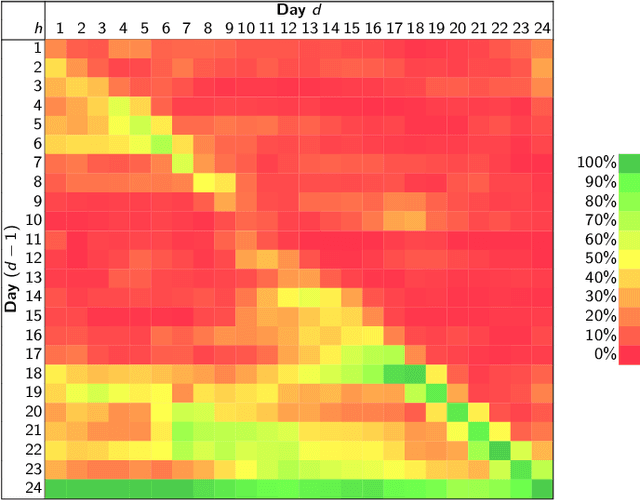
Forecasting electricity prices is a challenging task and an active area of research since the 1990s and the deregulation of the traditionally monopolistic and government-controlled power sectors. Although it aims at predicting both spot and forward prices, the vast majority of research is focused on short-term horizons which exhibit dynamics unlike in any other market. The reason is that power system stability calls for a constant balance between production and consumption, while being weather (both demand and supply) and business activity (demand only) dependent. The recent market innovations do not help in this respect. The rapid expansion of intermittent renewable energy sources is not offset by the costly increase of electricity storage capacities and modernization of the grid infrastructure. On the methodological side, this leads to three visible trends in electricity price forecasting research as of 2022. Firstly, there is a slow, but more noticeable with every year, tendency to consider not only point but also probabilistic (interval, density) or even path (also called ensemble) forecasts. Secondly, there is a clear shift from the relatively parsimonious econometric (or statistical) models towards more complex and harder to comprehend, but more versatile and eventually more accurate statistical/machine learning approaches. Thirdly, statistical error measures are nowadays regarded as only the first evaluation step. Since they may not necessarily reflect the economic value of reducing prediction errors, more and more often, they are complemented by case studies comparing profits from scheduling or trading strategies based on price forecasts obtained from different models.