 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergence of linguistic laws in human voice
Oct 09, 2016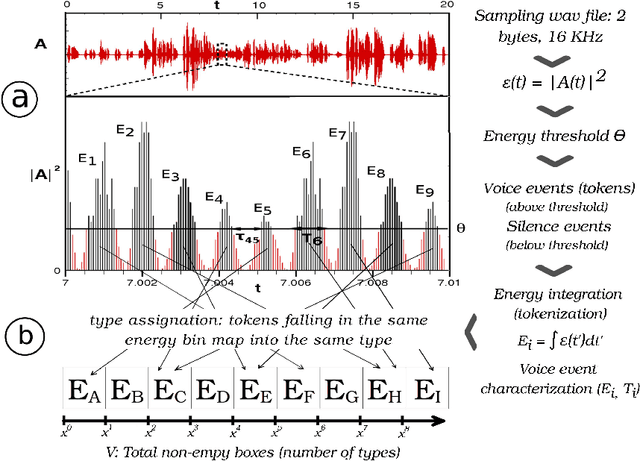
Linguistic laws constitute one of the quantitative cornerstones of modern cognitive sciences and have been routinely investigated in written corpora, or in the equivalent transcription of oral corpora. This means that inferences of statistical patterns of language in acoustics are biased by the arbitrary, language-dependent segmentation of the signal, and virtually precludes the possibility of making comparative studies between human voice and other animal communication systems. Here we bridge this gap by proposing a method that allows to measure such patterns in acoustic signals of arbitrary origin, without needs to have access to the language corpus underneath. The method has been applied to six different human languages, recovering successfully some well-known laws of human communication at timescales even below the phoneme and finding yet another link between complexity and criticality in a biological system. These methods further pave the way for new comparative studies in animal communication or the analysis of signals of unknown code.
Speech earthquakes: scaling and universality in human voice
Aug 05, 2014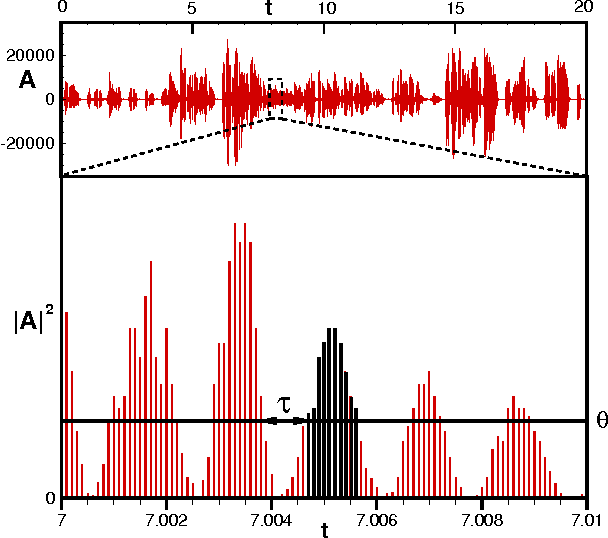
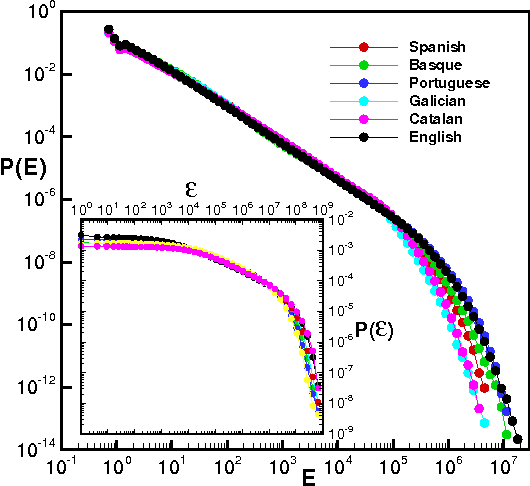
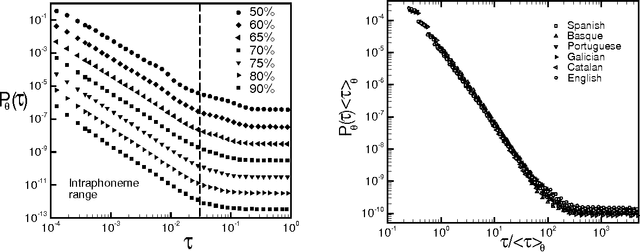
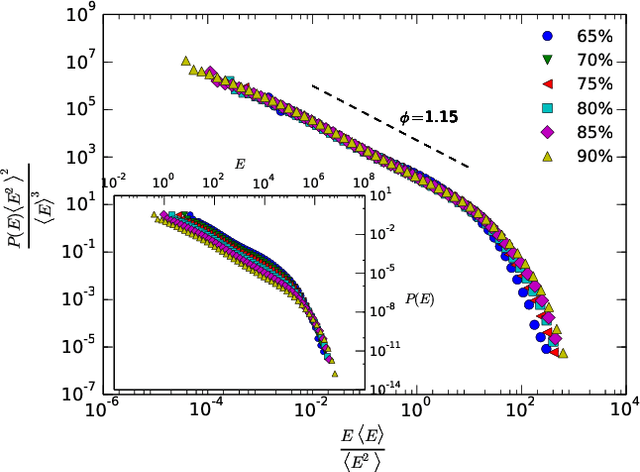
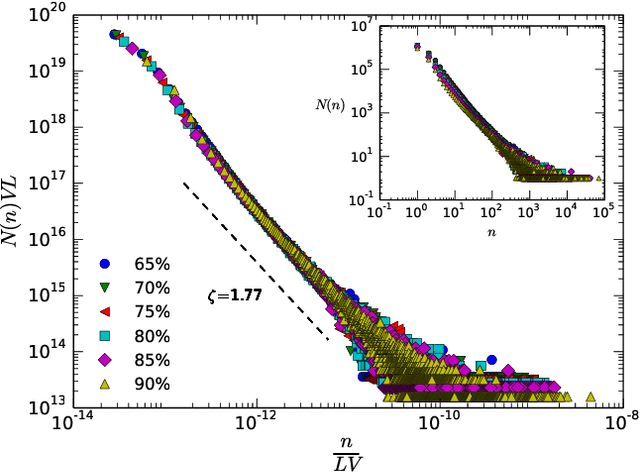
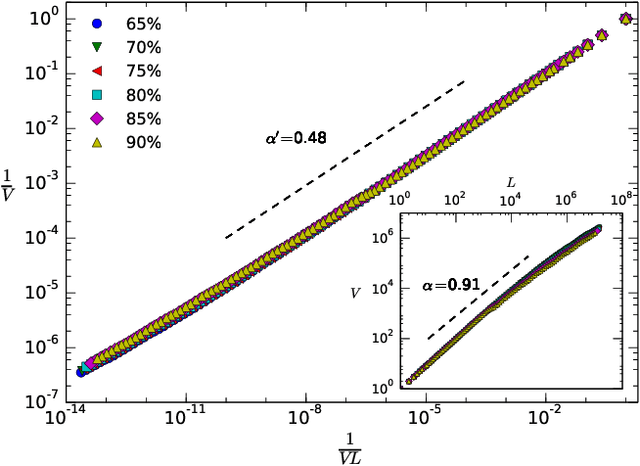
Speech is a distinctive complex feature of human capabilities. In order to understand the physics underlying speech production, in this work we empirically analyse the statistics of large human speech datasets ranging several languages. We first show that during speech the energy is unevenly released and power-law distributed, reporting a universal robust Gutenberg-Richter-like law in speech. We further show that such earthquakes in speech show temporal correlations, as the interevent statistics are again power-law distributed. Since this feature takes place in the intra-phoneme range, we conjecture that the responsible for this complex phenomenon is not cognitive, but it resides on the physiological speech production mechanism. Moreover, we show that these waiting time distributions are scale invariant under a renormalisation group transformation, suggesting that the process of speech generation is indeed operating close to a critical point. These results are put in contrast with current paradigms in speech processing, which point towards low dimensional deterministic chaos as the origin of nonlinear traits in speech fluctuations. As these latter fluctuations are indeed the aspects that humanize synthetic speech, these findings may have an impact in future speech synthesis technologies. Results are robust and independent of the communication language or the number of speakers, pointing towards an universal pattern and yet another hint of complexity in human speech.