 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Start Up a Start-Up$-$Embedding Strategic Demand Development in Operational On-Demand Fulfillment via Reinforcement Learning with Information Shaping
Apr 08, 2025The last few years have witnessed rapid growth in the on-demand delivery market, with many start-ups entering the field. However, not all of these start-ups have succeeded due to various reasons, among others, not being able to establish a large enough customer base. In this paper, we address this problem that many on-demand transportation start-ups face: how to establish themselves in a new market. When starting, such companies often have limited fleet resources to serve demand across a city. Depending on the use of the fleet, varying service quality is observed in different areas of the city, and in turn, the service quality impacts the respective growth of demand in each area. Thus, operational fulfillment decisions drive the longer-term demand development. To integrate strategic demand development into real-time fulfillment operations, we propose a two-step approach. First, we derive analytical insights into optimal allocation decisions for a stylized problem. Second, we use these insights to shape the training data of a reinforcement learning strategy for operational real-time fulfillment. Our experiments demonstrate that combining operational efficiency with long-term strategic planning is highly advantageous. Further, we show that the careful shaping of training data is essential for the successful development of demand.
An Explainable Deep Reinforcement Learning Model for Warfarin Maintenance Dosing Using Policy Distillation and Action Forging
Apr 26, 2024



Deep Reinforcement Learning is an effective tool for drug dosing for chronic condition management. However, the final protocol is generally a black box without any justification for its prescribed doses. This paper addresses this issue by proposing an explainable dosing protocol for warfarin using a Proximal Policy Optimization method combined with Policy Distillation. We introduce Action Forging as an effective tool to achieve explainability. Our focus is on the maintenance dosing protocol. Results show that the final model is as easy to understand and deploy as the current dosing protocols and outperforms the baseline dosing algorithms.
Optimizing Warfarin Dosing using Deep Reinforcement Learning
Feb 07, 2022
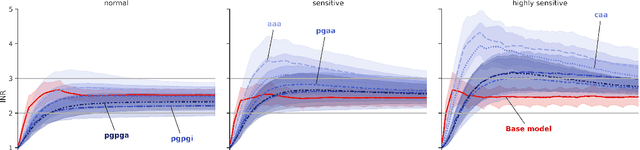

Warfarin is a widely used anticoagulant, and has a narrow therapeutic range. Dosing of warfarin should be individualized, since slight overdosing or underdosing can have catastrophic or even fatal consequences. Despite much research on warfarin dosing, current dosing protocols do not live up to expectations, especially for patients sensitive to warfarin. We propose a deep reinforcement learning-based dosing model for warfarin. To overcome the issue of relatively small sample sizes in dosing trials, we use a Pharmacokinetic/ Pharmacodynamic (PK/PD) model of warfarin to simulate dose-responses of virtual patients. Applying the proposed algorithm on virtual test patients shows that this model outperforms a set of clinically accepted dosing protocols by a wide margin.
Same-Day Delivery with Fairness
Jul 19, 2020


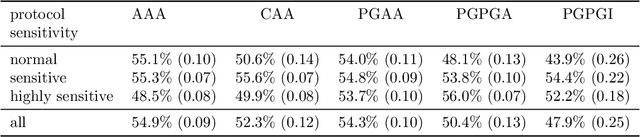
The demand for same-day delivery (SDD) has increased rapidly in the last few years and has particularly boomed during the COVID-19 pandemic. Existing literature on the problem has focused on maximizing the utility, represented as the total number of expected requests served. However, a utility-driven solution results in unequal opportunities for customers to receive delivery service, raising questions about fairness. In this paper, we study the problem of achieving fairness in SDD. We construct a regional-level fairness constraint that ensures customers from different regions have an equal chance of being served. We develop a reinforcement learning model to learn policies that focus on both overall utility and fairness. Experimental results demonstrate the ability of our approach to mitigate the unfairness caused by geographic differences and constraints of resources, at both coarser and finer-grained level and with a small cost to utility. In addition, we simulate a real-world situation where the system is suddenly overwhelmed by a surge of requests, mimicking the COVID-19 scenario. Our model is robust to the systematic pressure and is able to maintain fairness with little compromise to the utility.
Deep Q-Learning for Same-Day Delivery with a Heterogeneous Fleet of Vehicles and Drones
Oct 25, 2019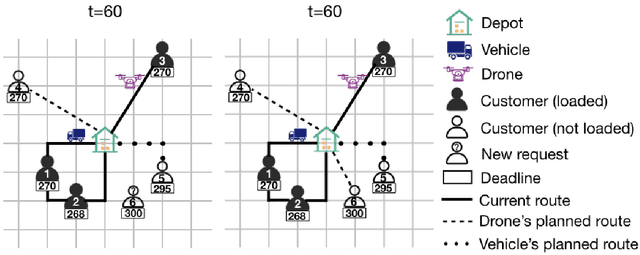
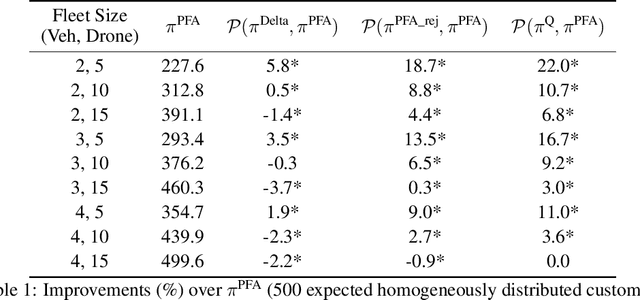
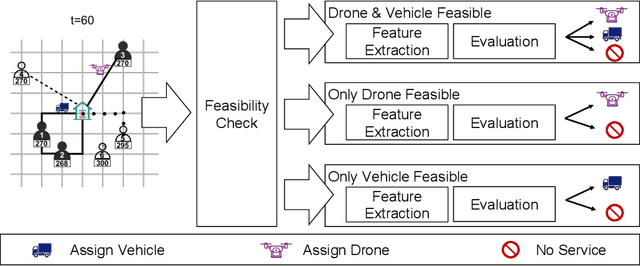

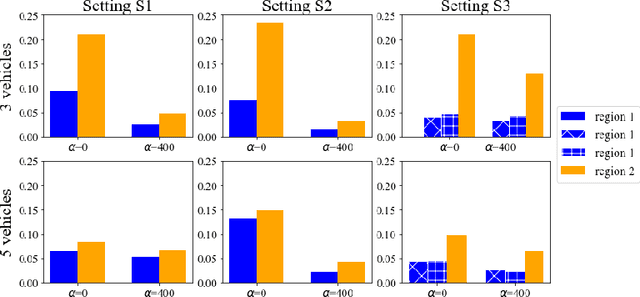
In this paper, we consider same-day delivery with a heterogeneous fleet of vehicles and drones. Customers make delivery requests over the course of the day and the dispatcher dynamically dispatches vehicles and drones to deliver the goods to customers before their delivery deadline. Vehicles can deliver multiple packages in one route but travel relatively slowly due to the urban traffic. Drones travel faster, but they have limited capacity and require charging or battery swaps. To exploit the different strengths of the fleets, we propose a deep Q-learning approach. Our method learns the value of assigning a new customer to either drones or vehicles as well as the option to not offer service at all. To aid feature selection, we present an analytical analysis that demonstrates the role that different types of information have on the value function and decision making. In a systematic computational analysis, we show the superiority of our policy compared to benchmark policies and the effectiveness of our deep Q-learning approach.