 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCervical Auscultation Machine Learning for Dysphagia Assessment
Jul 08, 2024



This study evaluates the use of machine learning, specifically the Random Forest Classifier, to differentiate normal and pathological swallowing sounds. Employing a commercially available wearable stethoscope, we recorded swallows from both healthy adults and patients with dysphagia. The analysis revealed statistically significant differences in acoustic features, such as spectral crest, and zero-crossing rate between normal and pathological swallows, while no discriminating differences were demonstrated between different fluidand diet consistencies. The system demonstrated fair sensitivity (mean plus or minus SD: 74% plus or minus 8%) and specificity (89% plus or minus 6%) for dysphagic swallows. The model attained an overall accuracy of 83% plus or minus 3%, and F1 score of 78% plus or minus 5%. These results demonstrate that machine learning can be a valuable tool in non-invasive dysphagia assessment, although challenges such as sampling rate limitations and variability in sensitivity and specificity in discriminating between normal and pathological sounds are noted. The study underscores the need for further research to optimize these techniques for clinical use.
Performance Assessment of ChatGPT vs Bard in Detecting Alzheimer's Dementia
Jan 30, 2024Large language models (LLMs) find increasing applications in many fields. Here, three LLM chatbots (ChatGPT-3.5, ChatGPT-4 and Bard) are assessed - in their current form, as publicly available - for their ability to recognize Alzheimer's Dementia (AD) and Cognitively Normal (CN) individuals using textual input derived from spontaneous speech recordings. Zero-shot learning approach is used at two levels of independent queries, with the second query (chain-of-thought prompting) eliciting more detailed than the first. Each LLM chatbot's performance is evaluated on the prediction generated in terms of accuracy, sensitivity, specificity, precision and F1 score. LLM chatbots generated three-class outcome ("AD", "CN", or "Unsure"). When positively identifying AD, Bard produced highest true-positives (89% recall) and highest F1 score (71%), but tended to misidentify CN as AD, with high confidence (low "Unsure" rates); for positively identifying CN, GPT-4 resulted in the highest true-negatives at 56% and highest F1 score (62%), adopting a diplomatic stance (moderate "Unsure" rates). Overall, three LLM chatbots identify AD vs CN surpassing chance-levels but do not currently satisfy clinical application.
Deep Neural Network Based Respiratory Pathology Classification Using Cough Sounds
Jun 23, 2021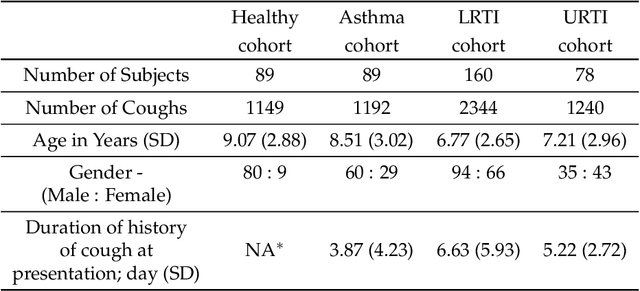

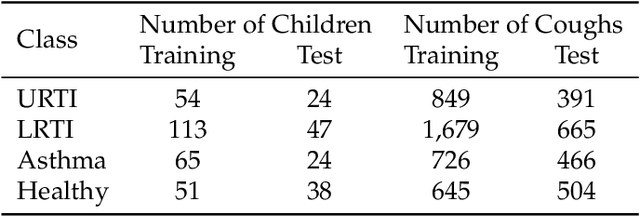
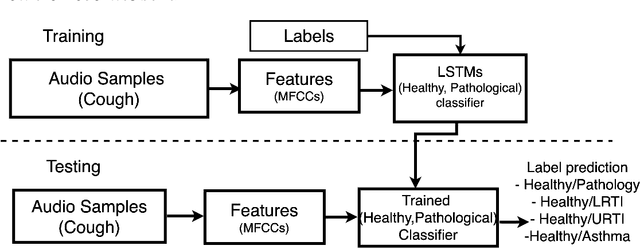
Intelligent systems are transforming the world, as well as our healthcare system. We propose a deep learning-based cough sound classification model that can distinguish between children with healthy versus pathological coughs such as asthma, upper respiratory tract infection (URTI), and lower respiratory tract infection (LRTI). In order to train a deep neural network model, we collected a new dataset of cough sounds, labelled with clinician's diagnosis. The chosen model is a bidirectional long-short term memory network (BiLSTM) based on Mel Frequency Cepstral Coefficients (MFCCs) features. The resulting trained model when trained for classifying two classes of coughs -- healthy or pathology (in general or belonging to a specific respiratory pathology), reaches accuracy exceeding 84\% when classifying cough to the label provided by the physicians' diagnosis. In order to classify subject's respiratory pathology condition, results of multiple cough epochs per subject were combined. The resulting prediction accuracy exceeds 91\% for all three respiratory pathologies. However, when the model is trained to classify and discriminate among the four classes of coughs, overall accuracy dropped: one class of pathological coughs are often misclassified as other. However, if one consider the healthy cough classified as healthy and pathological cough classified to have some kind of pathologies, then the overall accuracy of four class model is above 84\%. A longitudinal study of MFCC feature space when comparing pathological and recovered coughs collected from the same subjects revealed the fact that pathological cough irrespective of the underlying conditions occupy the same feature space making it harder to differentiate only using MFCC features.
Acoustic prediction of flowrate: varying liquid jet stream onto a free surface
Jun 16, 2020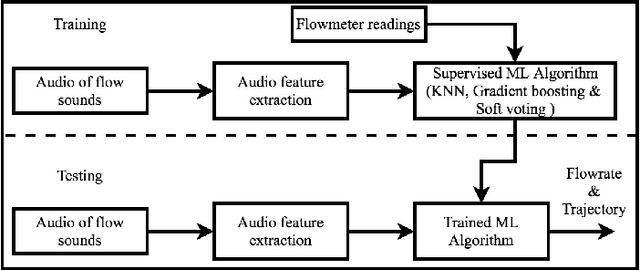

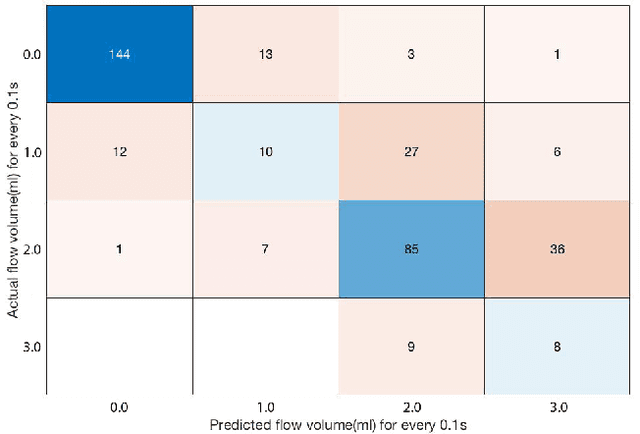
Information on liquid jet stream flow is crucial in many real world applications. In a large number of cases, these flows fall directly onto free surfaces (e.g. pools), creating a splash with accompanying splashing sounds. The sound produced is supplied by energy interactions between the liquid jet stream and the passive free surface. In this investigation, we collect the sound of a water jet of varying flowrate falling into a pool of water, and use this sound to predict the flowrate and flowrate trajectory involved. Two approaches are employed: one uses machine-learning models trained using audio features extracted from the collected sound to predict the flowrate (and subsequently the flowrate trajectory). In contrast, the second method directly uses acoustic parameters related to the spectral energy of the liquid-liquid interaction to estimate the flowrate trajectory. The actual flowrate, however, is determined directly using a gravimetric method: tracking the change in mass of the pooling liquid over time. We show here that the two methods agree well with the actual flowrate and offer comparable performance in accurately predicting the flowrate trajectory, and accordingly offer insights for potential real-life applications using sound.