 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXp-GAN: Unsupervised Multi-object Controllable Video Generation
Nov 19, 2021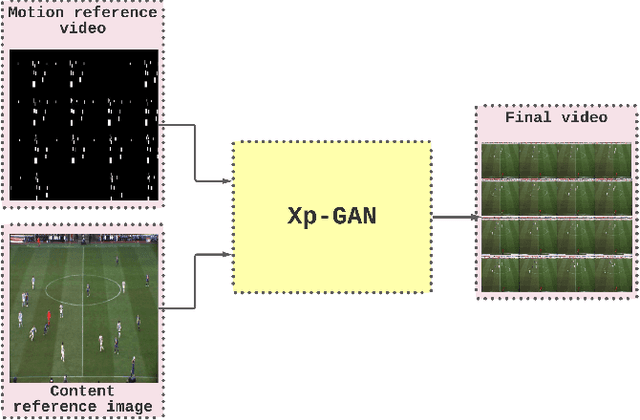

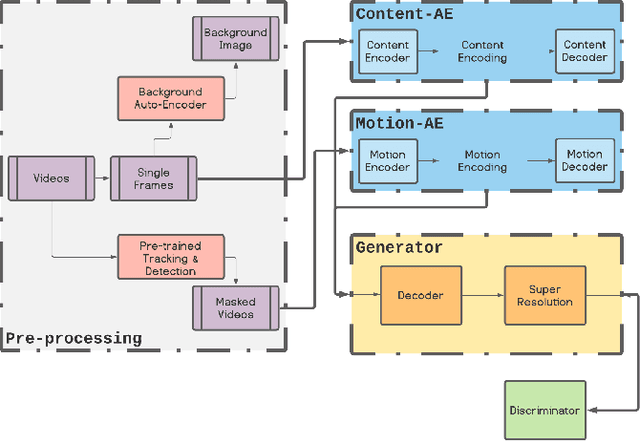
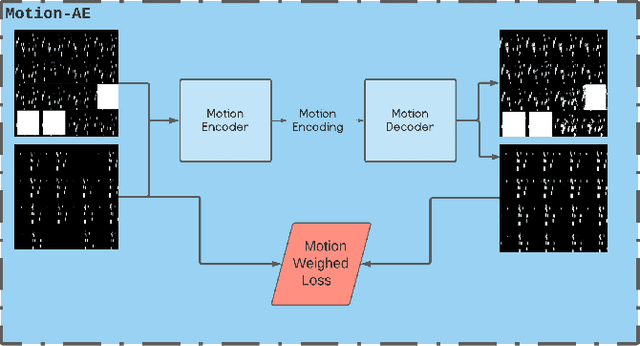
Video Generation is a relatively new and yet popular subject in machine learning due to its vast variety of potential applications and its numerous challenges. Current methods in Video Generation provide the user with little or no control over the exact specification of how the objects in the generate video are to be moved and located at each frame, that is, the user can't explicitly control how each object in the video should move. In this paper we propose a novel method that allows the user to move any number of objects of a single initial frame just by drawing bounding boxes over those objects and then moving those boxes in the desired path. Our model utilizes two Autoencoders to fully decompose the motion and content information in a video and achieves results comparable to well-known baseline and state of the art methods.