 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTreeDGS: Aerial Gaussian Splatting for Distant DBH Measurement
Jan 19, 2026Aerial remote sensing enables efficient large-area surveying, but accurate direct object-level measurement remains difficult in complex natural scenes. Recent advancements in 3D vision, particularly learned radiance-field representations such as NeRF and 3D Gaussian Splatting, have begun to raise the ceiling on reconstruction fidelity and densifiable geometry from posed imagery. Nevertheless, direct aerial measurement of important natural attributes such as tree diameter at breast height (DBH) remains challenging. Trunks in aerial forest scans are distant and sparsely observed in image views: at typical operating altitudes, stems may span only a few pixels. With these constraints, conventional reconstruction methods leave breast-height trunk geometry weakly constrained. We present TreeDGS, an aerial image reconstruction method that leverages 3D Gaussian Splatting as a continuous, densifiable scene representation for trunk measurement. After SfM-MVS initialization and Gaussian optimization, we extract a dense point set from the Gaussian field using RaDe-GS's depth-aware cumulative-opacity integration and associate each sample with a multi-view opacity reliability score. We then estimate DBH from trunk-isolated points using opacity-weighted solid-circle fitting. Evaluated on 10 plots with field-measured DBH, TreeDGS reaches 4.79,cm RMSE (about 2.6 pixels at this GSD) and outperforms a state-of-the-art LiDAR baseline (7.91,cm RMSE), demonstrating that densified splat-based geometry can enable accurate, low-cost aerial DBH measurement.
A-SCoRe: Attention-based Scene Coordinate Regression for wide-ranging scenarios
Mar 18, 2025Visual localization is considered to be one of the crucial parts in many robotic and vision systems. While state-of-the art methods that relies on feature matching have proven to be accurate for visual localization, its requirements for storage and compute are burdens. Scene coordinate regression (SCR) is an alternative approach that remove the barrier for storage by learning to map 2D pixels to 3D scene coordinates. Most popular SCR use Convolutional Neural Network (CNN) to extract 2D descriptor, which we would argue that it miss the spatial relationship between pixels. Inspired by the success of vision transformer architecture, we present a new SCR architecture, called A-ScoRe, an Attention-based model which leverage attention on descriptor map level to produce meaningful and high-semantic 2D descriptors. Since the operation is performed on descriptor map, our model can work with multiple data modality whether it is a dense or sparse from depth-map, SLAM to Structure-from-Motion (SfM). This versatility allows A-SCoRe to operate in different kind of environments, conditions and achieve the level of flexibility that is important for mobile robots. Results show our methods achieve comparable performance with State-of-the-art methods on multiple benchmark while being light-weighted and much more flexible. Code and pre-trained models are public in our repository: https://github.com/ais-lab/A-SCoRe.
Improved 3D Point-Line Mapping Regression for Camera Relocalization
Feb 28, 2025In this paper, we present a new approach for improving 3D point and line mapping regression for camera re-localization. Previous methods typically rely on feature matching (FM) with stored descriptors or use a single network to encode both points and lines. While FM-based methods perform well in large-scale environments, they become computationally expensive with a growing number of mapping points and lines. Conversely, approaches that learn to encode mapping features within a single network reduce memory footprint but are prone to overfitting, as they may capture unnecessary correlations between points and lines. We propose that these features should be learned independently, each with a distinct focus, to achieve optimal accuracy. To this end, we introduce a new architecture that learns to prioritize each feature independently before combining them for localization. Experimental results demonstrate that our approach significantly enhances the 3D map point and line regression performance for camera re-localization. The implementation of our method will be publicly available at: https://github.com/ais-lab/pl2map/.
Leveraging Neural Radiance Field in Descriptor Synthesis for Keypoints Scene Coordinate Regression
Mar 20, 2024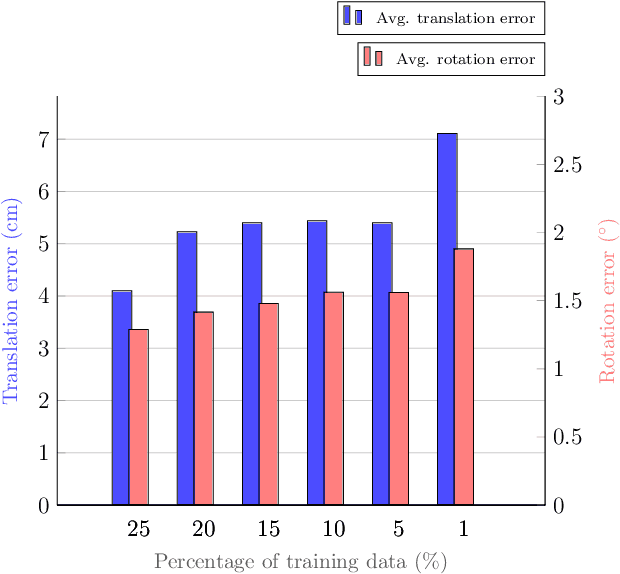
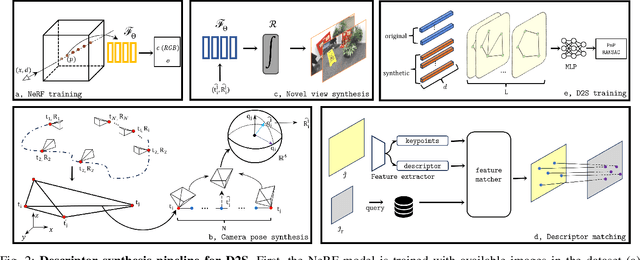
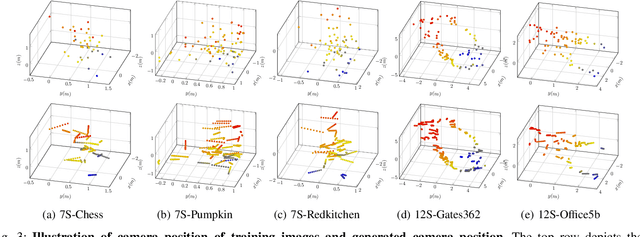

Classical structural-based visual localization methods offer high accuracy but face trade-offs in terms of storage, speed, and privacy. A recent innovation, keypoint scene coordinate regression (KSCR) named D2S addresses these issues by leveraging graph attention networks to enhance keypoint relationships and predict their 3D coordinates using a simple multilayer perceptron (MLP). Camera pose is then determined via PnP+RANSAC, using established 2D-3D correspondences. While KSCR achieves competitive results, rivaling state-of-the-art image-retrieval methods like HLoc across multiple benchmarks, its performance is hindered when data samples are limited due to the deep learning model's reliance on extensive data. This paper proposes a solution to this challenge by introducing a pipeline for keypoint descriptor synthesis using Neural Radiance Field (NeRF). By generating novel poses and feeding them into a trained NeRF model to create new views, our approach enhances the KSCR's generalization capabilities in data-scarce environments. The proposed system could significantly improve localization accuracy by up to 50% and cost only a fraction of time for data synthesis. Furthermore, its modular design allows for the integration of multiple NeRFs, offering a versatile and efficient solution for visual localization. The implementation is publicly available at: https://github.com/ais-lab/DescriptorSynthesis4Feat2Map.
Representing 3D sparse map points and lines for camera relocalization
Feb 28, 2024Recent advancements in visual localization and mapping have demonstrated considerable success in integrating point and line features. However, expanding the localization framework to include additional mapping components frequently results in increased demand for memory and computational resources dedicated to matching tasks. In this study, we show how a lightweight neural network can learn to represent both 3D point and line features, and exhibit leading pose accuracy by harnessing the power of multiple learned mappings. Specifically, we utilize a single transformer block to encode line features, effectively transforming them into distinctive point-like descriptors. Subsequently, we treat these point and line descriptor sets as distinct yet interconnected feature sets. Through the integration of self- and cross-attention within several graph layers, our method effectively refines each feature before regressing 3D maps using two simple MLPs. In comprehensive experiments, our indoor localization findings surpass those of Hloc and Limap across both point-based and line-assisted configurations. Moreover, in outdoor scenarios, our method secures a significant lead, marking the most considerable enhancement over state-of-the-art learning-based methodologies. The source code and demo videos of this work are publicly available at: https://thpjp.github.io/pl2map/
D2S: Representing local descriptors and global scene coordinates for camera relocalization
Jul 28, 2023



State-of-the-art visual localization methods mostly rely on complex procedures to match local descriptors and 3D point clouds. However, these procedures can incur significant cost in terms of inference, storage, and updates over time. In this study, we propose a direct learning-based approach that utilizes a simple network named D2S to represent local descriptors and their scene coordinates. Our method is characterized by its simplicity and cost-effectiveness. It solely leverages a single RGB image for localization during the testing phase and only requires a lightweight model to encode a complex sparse scene. The proposed D2S employs a combination of a simple loss function and graph attention to selectively focus on robust descriptors while disregarding areas such as clouds, trees, and several dynamic objects. This selective attention enables D2S to effectively perform a binary-semantic classification for sparse descriptors. Additionally, we propose a new outdoor dataset to evaluate the capabilities of visual localization methods in terms of scene generalization and self-updating from unlabeled observations. Our approach outperforms the state-of-the-art CNN-based methods in scene coordinate regression in indoor and outdoor environments. It demonstrates the ability to generalize beyond training data, including scenarios involving transitions from day to night and adapting to domain shifts, even in the absence of the labeled data sources. The source code, trained models, dataset, and demo videos are available at the following link: https://thpjp.github.io/d2s