 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA coherence parameter characterizing generative compressed sensing with Fourier measurements
Jul 19, 2022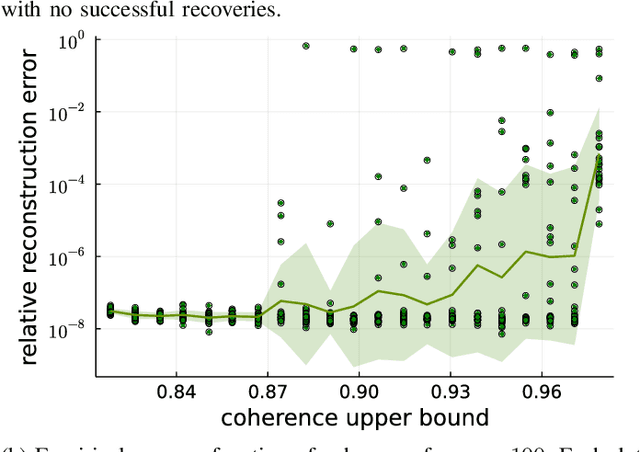

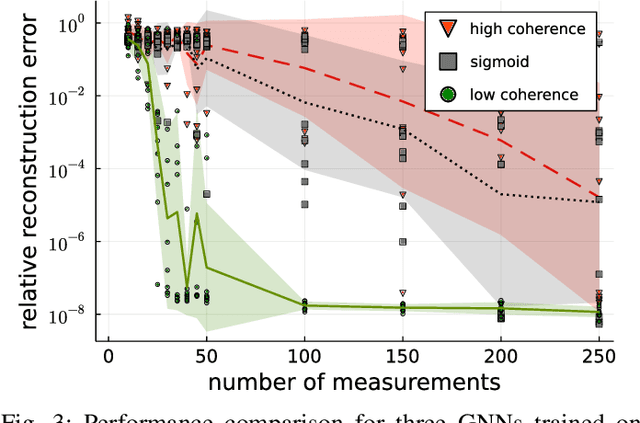
In Bora et al. (2017), a mathematical framework was developed for compressed sensing guarantees in the setting where the measurement matrix is Gaussian and the signal structure is the range of a generative neural network (GNN). The problem of compressed sensing with GNNs has since been extensively analyzed when the measurement matrix and/or network weights follow a subgaussian distribution. We move beyond the subgaussian assumption, to measurement matrices that are derived by sampling uniformly at random rows of a unitary matrix (including subsampled Fourier measurements as a special case). Specifically, we prove the first known restricted isometry guarantee for generative compressed sensing with subsampled isometries, and provide recovery bounds with nearly order-optimal sample complexity, addressing an open problem of Scarlett et al. (2022, p. 10). Recovery efficacy is characterized by the coherence, a new parameter, which measures the interplay between the range of the network and the measurement matrix. Our approach relies on subspace counting arguments and ideas central to high-dimensional probability. Furthermore, we propose a regularization strategy for training GNNs to have favourable coherence with the measurement operator. We provide compelling numerical simulations that support this regularized training strategy: our strategy yields low coherence networks that require fewer measurements for signal recovery. This, together with our theoretical results, supports coherence as a natural quantity for characterizing generative compressed sensing with subsampled isometries.
Global Guarantees for Blind Demodulation with Generative Priors
May 29, 2019

We study a deep learning inspired formulation for the blind demodulation problem, which is the task of recovering two unknown vectors from their entrywise multiplication. We consider the case where the unknown vectors are in the range of known deep generative models, $\mathcal{G}^{(1)}:\mathbb{R}^n\rightarrow\mathbb{R}^\ell$ and $\mathcal{G}^{(2)}:\mathbb{R}^p\rightarrow\mathbb{R}^\ell$. In the case when the networks corresponding to the generative models are expansive, the weight matrices are random and the dimension of the unknown vectors satisfy $\ell = \Omega(n^2+p^2)$, up to log factors, we show that the empirical risk objective has a favorable landscape for optimization. That is, the objective function has a descent direction at every point outside of a small neighborhood around four hyperbolic curves. We also characterize the local maximizers of the empirical risk objective and, hence, show that there does not exist any other stationary points outside of these neighborhood around four hyperbolic curves and the set of local maximizers. We also implement a gradient descent scheme inspired by the geometry of the landscape of the objective function. In order to converge to a global minimizer, this gradient descent scheme exploits the fact that exactly one of the hyperbolic curve corresponds to the global minimizer, and thus points near this hyperbolic curve have a lower objective value than points close to the other spurious hyperbolic curves. We show that this gradient descent scheme can effectively remove distortions synthetically introduced to the MNIST dataset.
A Convex Program for Mixed Linear Regression with a Recovery Guarantee for Well-Separated Data
Dec 21, 2017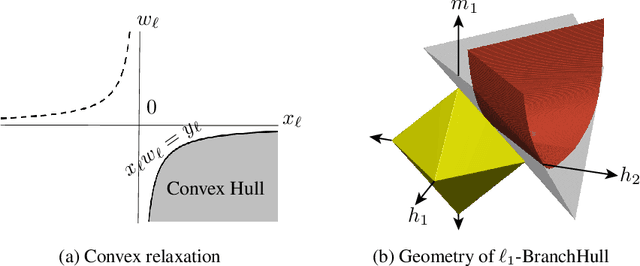
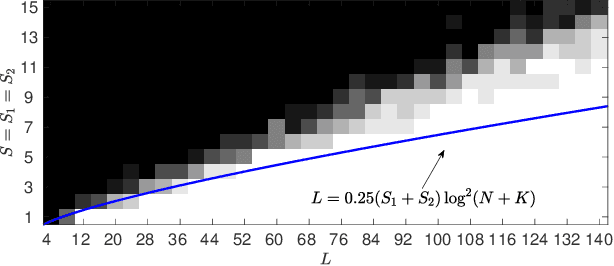

We introduce a convex approach for mixed linear regression over $d$ features. This approach is a second-order cone program, based on L1 minimization, which assigns an estimate regression coefficient in $\mathbb{R}^{d}$ for each data point. These estimates can then be clustered using, for example, $k$-means. For problems with two or more mixture classes, we prove that the convex program exactly recovers all of the mixture components in the noiseless setting under technical conditions that include a well-separation assumption on the data. Under these assumptions, recovery is possible if each class has at least $d$ independent measurements. We also explore an iteratively reweighted least squares implementation of this method on real and synthetic data.