 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFarsTail: A Persian Natural Language Inference Dataset
Sep 18, 2020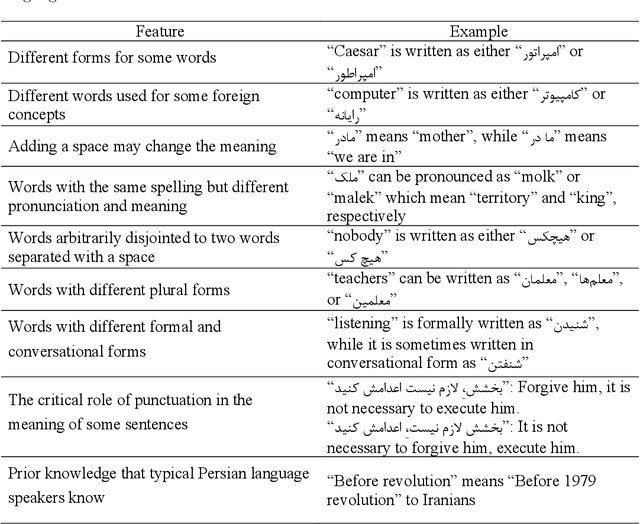
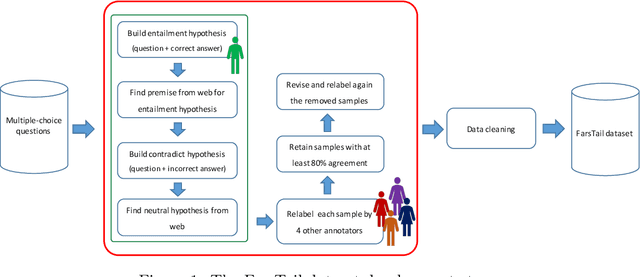

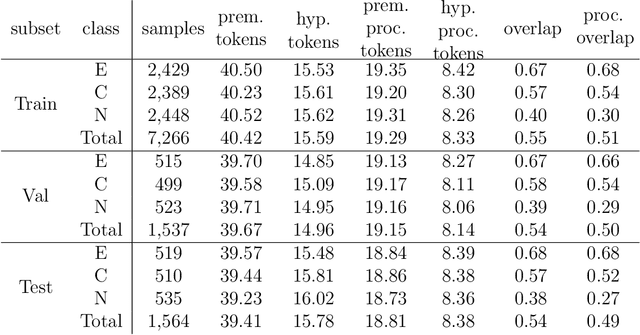
Natural language inference (NLI) is known as one of the central tasks in natural language processing (NLP) which encapsulates many fundamental aspects of language understanding. With the considerable achievements of data-hungry deep learning methods in NLP tasks, a great amount of effort has been devoted to develop more diverse datasets for different languages. In this paper, we present a new dataset for the NLI task in the Persian language, also known as Farsi, which is one of the dominant languages in the Middle East. This dataset, named FarsTail, includes 10,367 samples which are provided in both the Persian language as well as the indexed format to be useful for non-Persian researchers. The samples are generated from 3,539 multiple-choice questions with the least amount of annotator interventions in a way similar to the SciTail dataset. A carefully designed multi-step process is adopted to ensure the quality of the dataset. We also present the results of traditional and state-of-the-art methods on FarsTail including different embedding methods such as word2vec, fastText, ELMo, BERT, and LASER, as well as different modeling approaches such as DecompAtt, ESIM, HBMP, ULMFiT, and cross-lingual transfer approach to provide a solid baseline for the future research. The best obtained test accuracy is 78.13% which shows that there is a big room for improving the current methods to be useful for real-world NLP applications in different languages. The dataset is available at https://github.com/dml-qom/FarsTail.